
Teaser: Plato's allegory of the cave. Image Credit: Wikipedia
Note: This keynote summary is still in progress and represents ongoing research in the field of world modeling.
Introduction
World models have become a cornerstone in artificial intelligence research, enabling agents to understand, represent, and predict the dynamic environments they inhabit. This blog post explores recent advances in world modeling, from video generation to representation learning, and discusses emerging paradigms like the Platonic representation hypothesis.
Background and Related Works on World Modeling
The field of world modeling encompasses various approaches to generating and understanding 3D and 4D representations of the world. Recent surveys have categorized these approaches into three main paradigms:
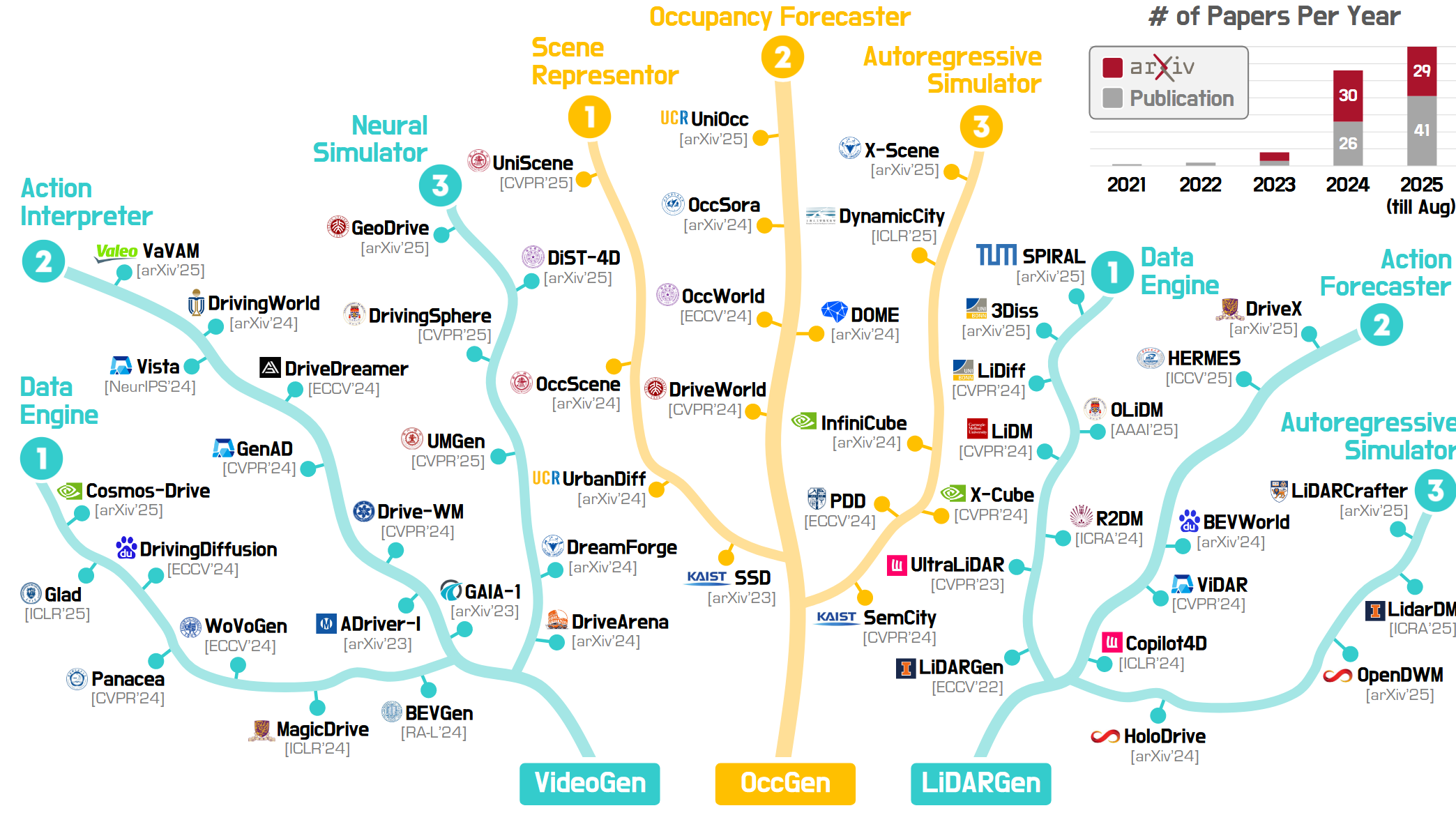
- VideoGen: Video-based world generation models that learn from visual sequences
- OccGen: Occupancy-based models that represent 3D space
- LiDARGen: LiDAR-based models for spatial understanding
VideoGen: CogVideoX
CogVideoX represents a significant advancement in text-to-video generation using diffusion transformers. This model can generate coherent, high-resolution videos (768×1360 pixels) at 16 fps for 10 seconds, with seamless alignment to text prompts.

Key Innovations
- 3D Variational Autoencoder (VAE): Compresses videos across both spatial and temporal dimensions, enhancing compression rate and video fidelity
- Expert Transformer: Features expert adaptive LayerNorm to facilitate deep fusion between text and video modalities
- Progressive Training: Uses multi-resolution frame packing to generate coherent, long-duration videos with diverse movements
Using CogVideoX for Image Editing: Frame2Frame
An intriguing application of video generation models is in image editing. The Frame2Frame method demonstrates how large video generation models can be repurposed for image manipulation tasks.
Intuition
The key insight is that sequences of frames in video clips reflect real-world physics with strong image consistency. By leveraging this property, we can treat image editing as a path through a video sequence.

This approach treats the input and target images as the first and last frames of a video, allowing the model to generate physically plausible transformations between them.
Representation Learning: CLIP
CLIP (Contrastive Language-Image Pre-training) represents a breakthrough in joint visual and semantic representation learning. It demonstrates how models can learn aligned representations across different modalities.
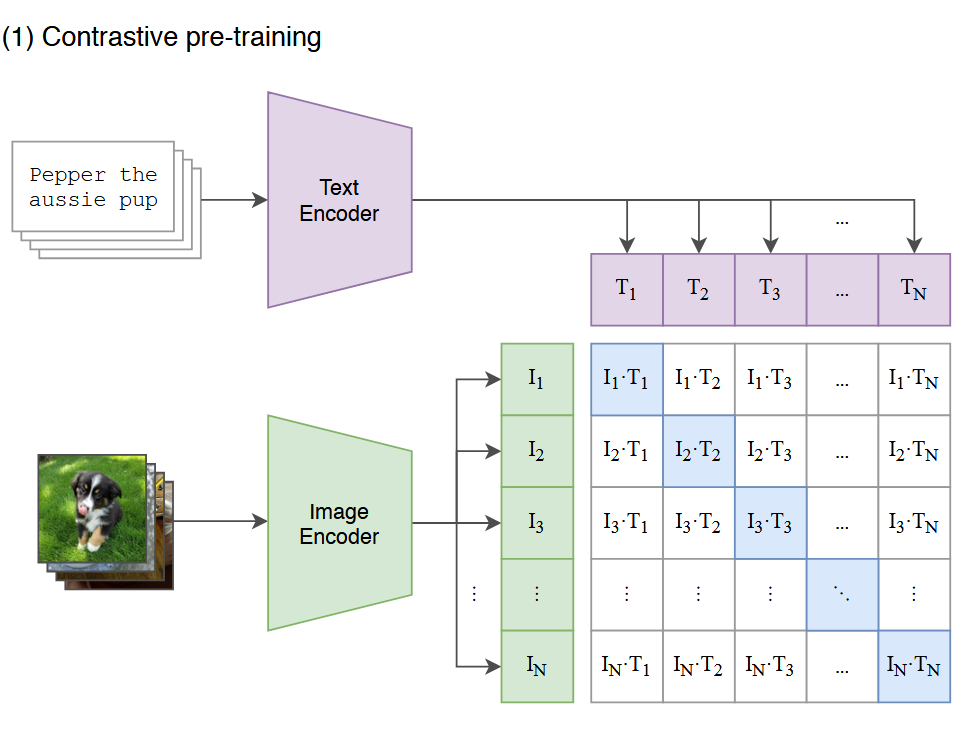
Overview of CLIP: A novel example of joint visual and semantic representation learning. [Radford et al., 2021]
CLIP learns to map both images and text into a shared embedding space, enabling zero-shot transfer across various vision tasks. This shared representation space allows the model to understand and relate concepts across modalities without task-specific training.
The Platonic Representation Hypothesis
The Platonic representation hypothesis proposes that AI models, particularly deep networks, are converging toward a shared statistical model of reality—akin to Plato’s concept of ideal forms.
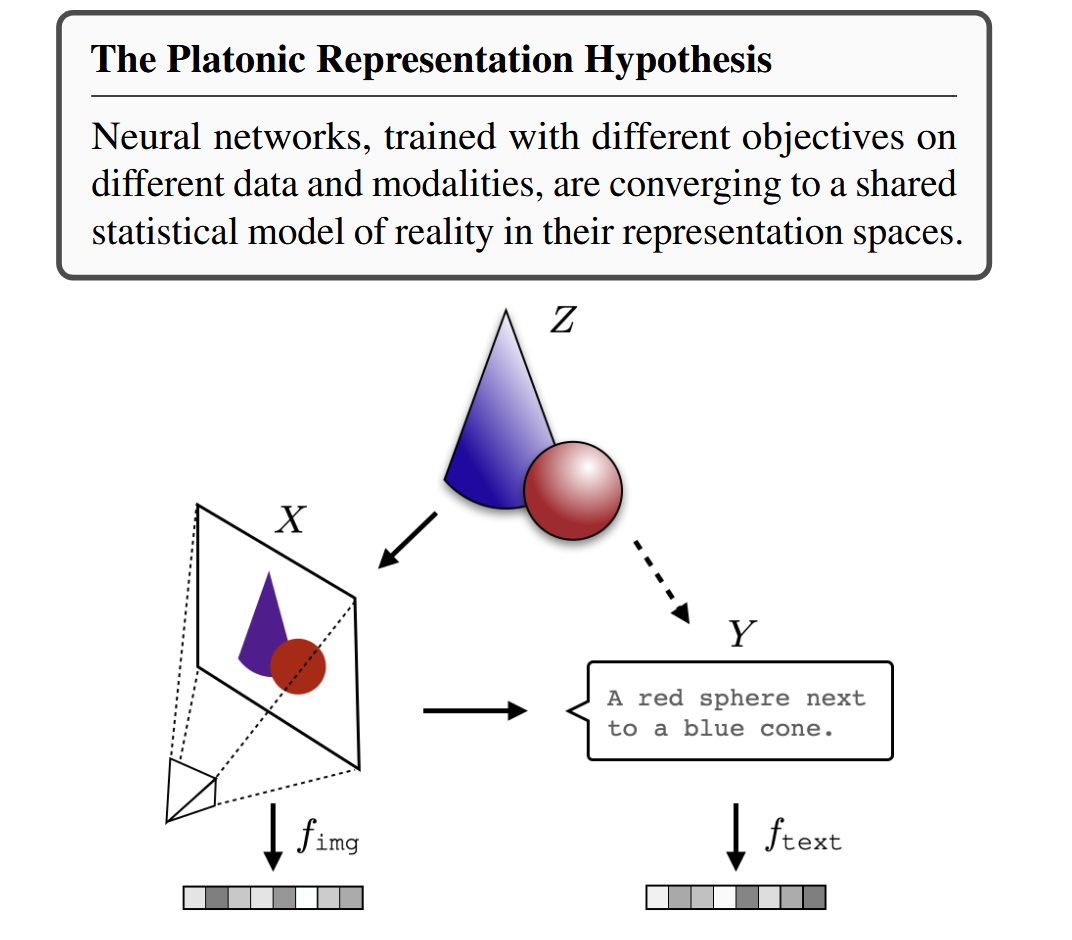
Core Hypothesis
The Platonic Representation Hypothesis: Images (X) and text (Y) are projections of a common underlying reality (Z).
This hypothesis suggests that as AI models become more sophisticated, their representations converge toward a shared understanding of the underlying structure of reality, regardless of the input modality (vision, language, etc.).
Evidence for Convergence
Recent research shows that:
- Cross-modal alignment: Vision and language models increasingly measure distances between datapoints in similar ways as they scale up
- Temporal convergence: Over time, different neural network architectures learn to represent data in more aligned ways
- Universal features: Larger models tend to discover similar fundamental features across different training objectives
This convergence suggests that there may be an optimal way to represent reality that all sufficiently powerful models will eventually discover—a “platonic” ideal representation.
Implications and Future Directions
The developments in world modeling have profound implications for artificial intelligence:
- Unified Multimodal Understanding: Models like CogVideoX and CLIP demonstrate the power of learning from multiple modalities simultaneously
- Physical Consistency: Video generation models inherently learn physical constraints, making them valuable for tasks requiring world simulation
- Zero-shot Transfer: Shared representations enable models to generalize across tasks without task-specific training
- World Simulation: These models could enable more sophisticated agents capable of reasoning about and predicting future states
Open Challenges
Despite recent progress, several challenges remain:
- Computational Efficiency: Generating high-resolution, long-duration videos remains computationally expensive
- Fine-grained Control: Better methods are needed for precise control over generation processes
- Physical Plausibility: Ensuring generated content respects real-world physics constraints
- Evaluation Metrics: Developing comprehensive metrics for assessing world model quality
Conclusion
World models represent a fascinating frontier in AI research, bridging perception, generation, and reasoning. From video generation with CogVideoX to the philosophical implications of the Platonic hypothesis, these developments hint at a future where AI systems can truly understand and simulate the world around them.
As these models continue to evolve, they promise to enable more sophisticated applications in areas ranging from creative content generation to robotic planning and beyond.
References
-
Kong, L., Yang, W., Mei, J., et al. (2025). 3D and 4D World Modeling: A Survey. arXiv:2509.07996
-
Yang, Z., Teng, J., Zheng, W., et al. (2025). CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer. In Proceedings of ICLR 2025
-
Rotstein, N., Yona, G., Silver, D., et al. (2025). Pathways on the Image Manifold: Image Editing via Video Generation. In Proceedings of CVPR 2025, pp. 7857-7866
-
Radford, A., Kim, J. W., Hallacy, C., et al. (2021). Learning Transferable Visual Models From Natural Language Supervision. In Proceedings of ICML 2021, pp. 8748-8763
-
Huh, M., Cheung, B., Wang, T., & Isola, P. (2024). Position: The Platonic Representation Hypothesis. In Proceedings of ICML 2024
Contact: bili_sakura@zju.edu.cn
© 2025 Sakura