About this keynote: This post summarizes a survey-style introduction to visual generation, tracing how deep generative models extend from unconditional image synthesis toward increasingly rich conditional controls and advanced applications.
Preliminary
Deep Generative Models
In early days, people from different groups explored visual generative models via denoising diffusion probabilistic models (DDPM) [Ho et al., 2020] and score-based generative models (NCSN) [Song and Ermon, 2019]. Later on, they were interpreted under the same framework called Score-SDE [Song et al., 2021]. After that, novel frameworks such as Flow Matching [Lipman et al., 2023] emerged, which are out of the scope of Score-SDE.

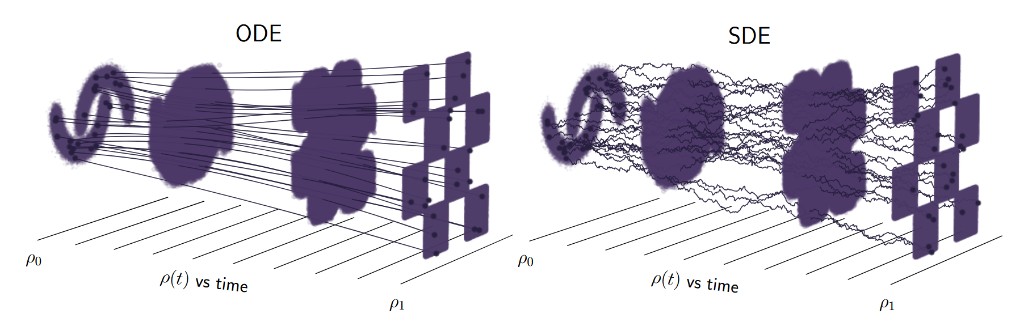
Nowadays, a promising unified framework called stochastic interpolants [Albergo et al., 2025] unifies most generative modeling frameworks. However, there is still a lack of common sense to name all these model groups with a unified category. Hence, for simplicity and clarity, we refer to them as deep generative models throughout this presentation.

Outline
- Unconditional/Class-Conditional Image Generation
- Text-to-Image Generation
- Controllable Image Generation
- Image Editing
- Image-to-Image Translation
- Video Generation
- Advanced Applications
- Inversion Task
- Representation Extractor
- Generalist Vision Learner
- 3D/4D Generation & World Modeling
- etc.
One Training Objective
“There is only one precise way of presenting the laws, and that is by means of differential equations. They have the advantage of being fundamental and, so far as we know, precise.”
— Richard P. Feynman
Many deep generative models share one training recipe [Lai et al., 2025]: fit a network to a noisy version of the data, weighted over time.
\[\mathcal{L}(\phi) := \mathbb{E}_{\mathbf{x}_0,\,\boldsymbol{\epsilon}} \left[ \underbrace{ \mathbb{E}_{p_{\mathrm{time}}(t)} }_{\text{time distribution}} \left[ \underbrace{ \omega(t) }_{\text{time weighting}} \underbrace{ \left\| \mathrm{NN}_{\phi}\!\bigl(\mathbf{x}_t, t\bigr) - \bigl(A_t \mathbf{x}_0 + B_t \boldsymbol{\epsilon}\bigr) \right\|_2^2 }_{\text{MSE part}} \right] \right]\]The design space can be summarized along four axes:
- (A) Noise schedule in the forward process of ( \mathbf{x}_t ) via ( \alpha_t ) and ( \sigma_t ).
- (B) Prediction types of ( \mathrm{NN}_{\phi} ) and regression targets ( \bigl(A_t \mathbf{x}_0 + B_t \boldsymbol{\epsilon}\bigr) ).
- (C) Time-weighting function ( \omega(\cdot) : [0, T] \to \mathbb{R}_{\geq 0} ).
- (D) Time distribution ( p_{\mathrm{time}} ).
Unconditional Image Generation
This section covers ( p(\mathbf{x}) ) and class-conditional ( p(\mathbf{x} \mid c) ), where ( c ) is a discrete class label (e.g., an ImageNet category)—not a text prompt or visual control signal.

| Res. | Model | FID | sFID | Prec | Rec |
|---|---|---|---|---|---|
| 128² | BigGAN-deep | 6.02 | 7.18 | 0.86 | 0.35 |
| ADM-G | 2.97 | 5.09 | 0.78 | 0.59 | |
| ADM-U | 5.91 | 5.09 | 0.70 | 0.65 | |
| 256² | BigGAN-deep | 6.95 | 7.36 | 0.87 | 0.28 |
| ADM-G | 4.59 | 5.25 | 0.82 | 0.52 | |
| ADM-U | 10.94 | 6.02 | 0.69 | 0.63 | |
| 512² | BigGAN-deep | 8.43 | 8.13 | 0.88 | 0.29 |
| ADM-G | 7.72 | 6.57 | 0.87 | 0.42 | |
| ADM-U | 23.24 | 10.19 | 0.73 | 0.60 |
Text-to-Image Generation
Synthesize images from natural language descriptions. Latent Diffusion Models (LDM; Stable Diffusion) [Rombach et al., 2022] led the era of latent modeling in research and AIGC in business.
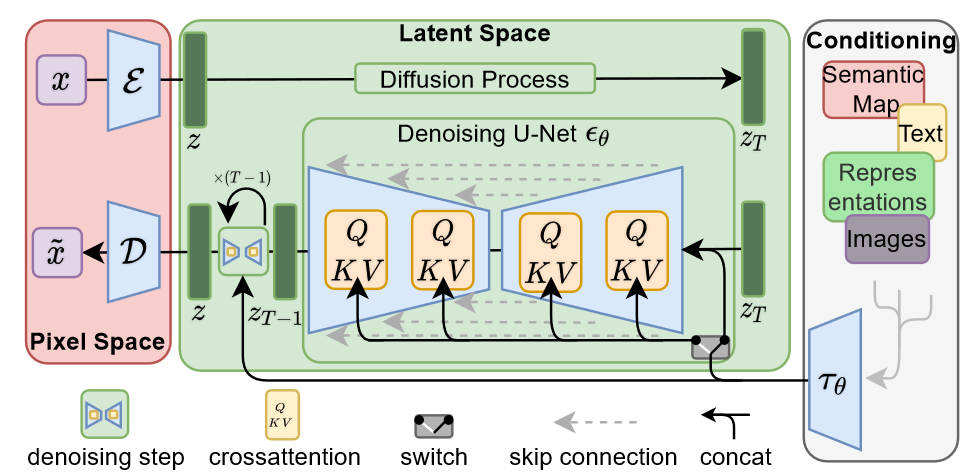
Controllable Image Generation
Steer generation with spatial, structural, or semantic controls. ControlNet [Zhang et al., 2023] injects auxiliary conditions (e.g., edges, pose) into a frozen diffusion U-Net.

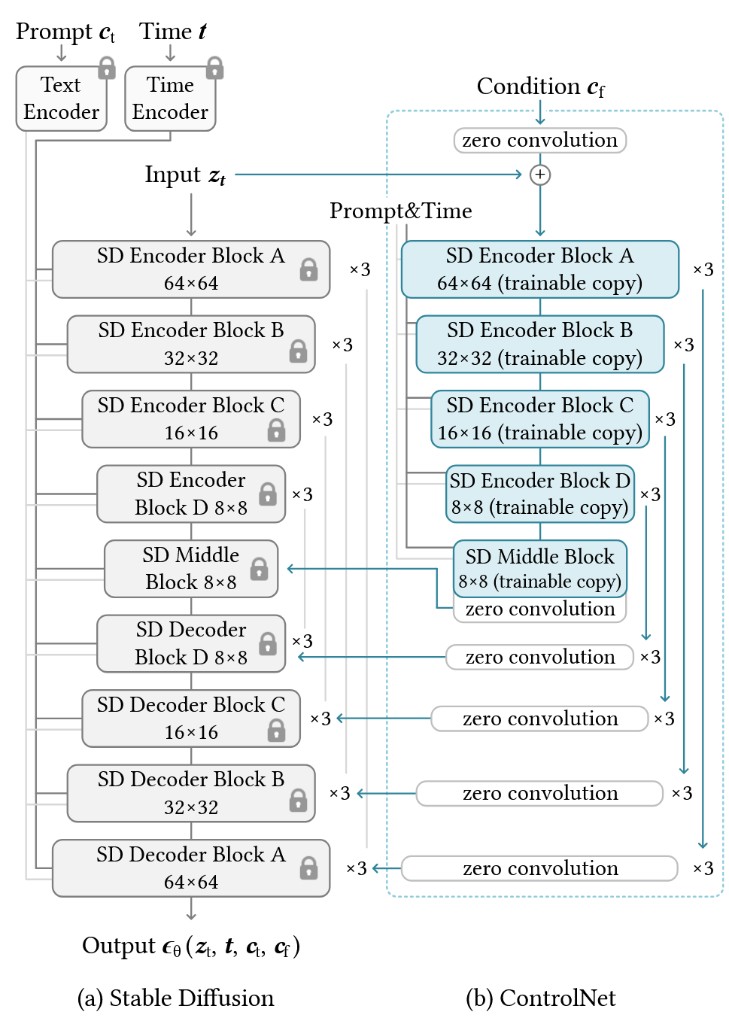
Image Editing
Move from text-to-image ( p(x\mid c_T) ) to instruction-guided editing ( p(x\mid c_T, c_I) ), where ( c_I ) is the input image. InstructPix2Pix [Brooks et al., 2023] concatenates the input image latent with the noisy latent along the channel dimension, introducing ( < )0.1M trainable parameters.

Image-to-Image Translation
Translate images across domains by learning a diffusion bridge between source and target distributions. DDBM [Zhou et al., 2024] generalizes score-based diffusion to Schrödinger-bridge image translation.

Video Generation
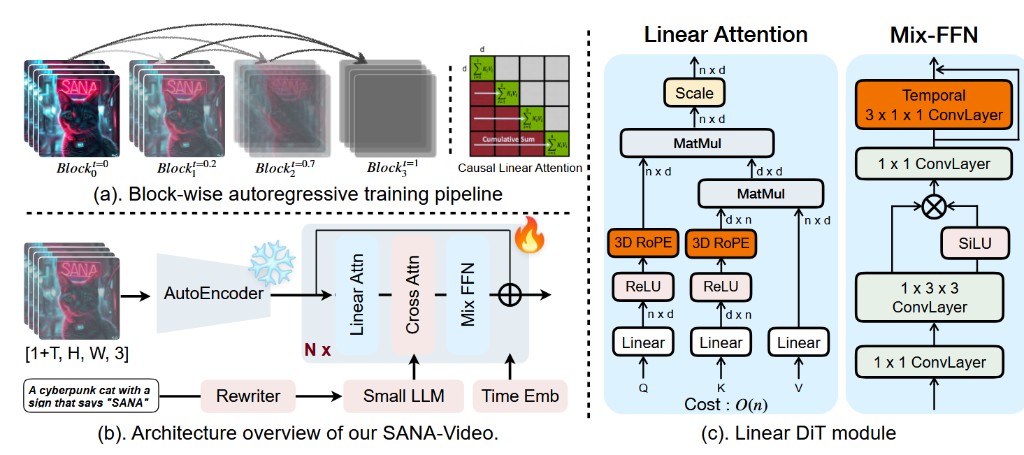
Extend image generation to coherent temporal synthesis with efficient diffusion transformers. SANA-Video [Chen et al., 2026] uses a deep compression VAE for spatiotemporal latent modeling, together with block linear DiT and autoregressive block training for efficient text-to-video generation.
Advanced Applications
Beyond standard synthesis: inversion, representation learning, and world modeling.
Inversion Task
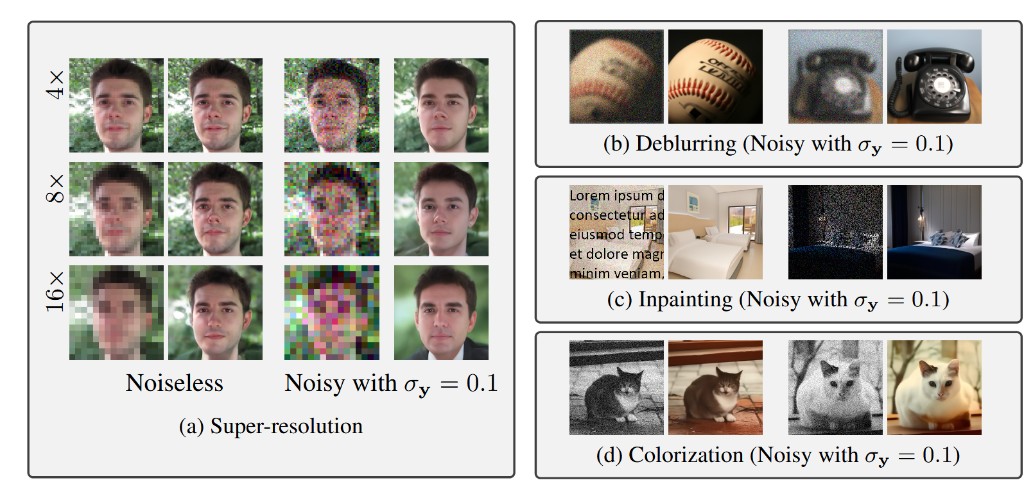
Solve inverse problems with a pre-trained diffusion generative model—no further training required. DDRM [Kawar et al., 2022] restores images from degraded observations via diffusion priors.
Representation Extractor
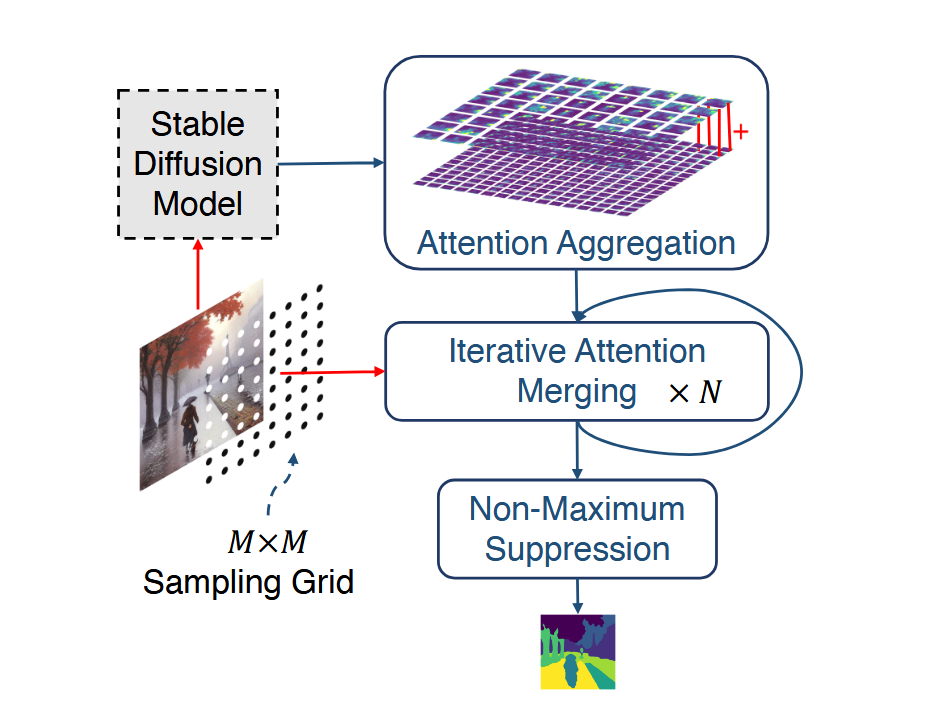
Use pre-trained diffusion models as representation extractors. DiffSeg [Tian et al., 2024] performs zero-shot segmentation from Stable Diffusion attention maps.

Generalist Vision Learner
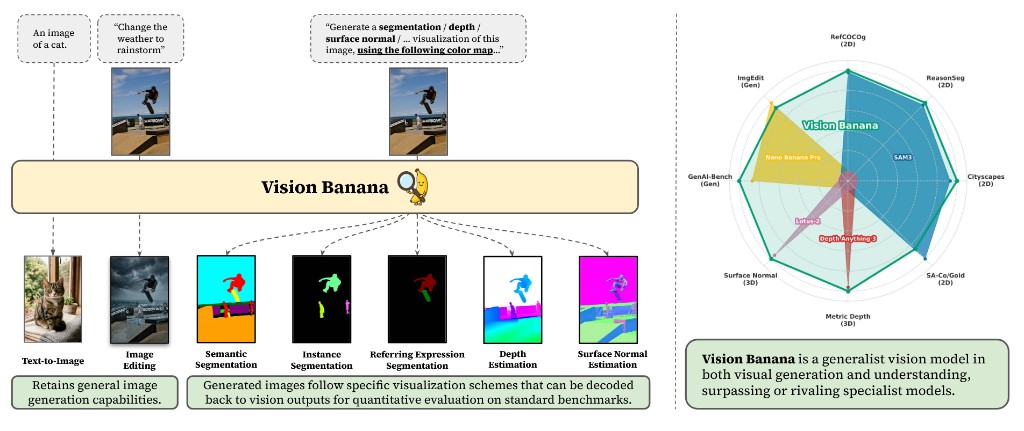
Build unified vision systems from large-scale generative pre-training. Vision Banana [Gabeur et al., 2026] shows image generators can be generalist vision learners for both generation and understanding.
3D/4D Generation & World Modeling
Generate navigable spatiotemporal worlds and learn interactive environment models from video. YUME 1.5 [Mao et al., 2025] extends YUME [Mao et al., 2025] with text-controlled exploration, trained on Sekai [Li et al., 2025].

Takeaways
- We start from an unconditional image generator ( p(x) ) and progressively add more conditions to it. Technically, this is representation alignment: new condition signals—text, segmentation maps, source images, etc.—are injected into a pre-trained denoiser.
- Besides their powerful generative capability, deep generative models are also representation learners [Yang and Wang, 2023], often matching or even surpassing SSL methods such as MoCo on downstream recognition.
- Joint generative modeling ( p(x,y) ) can natively unify generation and understanding via Bayes’ rule: marginalize to obtain ( p(x)=\int p(x,y)\,dy ) for synthesis, and derive ( p(y\mid x)=p(x,y)/p(x) ) for discriminative inference—without training a separate head. A more robust foundation model built on this principle remains under-explored.
- We are still on the way toward a generalist, task-agnostic, any-to-any foundation model [Gabeur et al., 2026], [Zuo et al., 2025].
- Building strong generative models is promising and already feasible, but open challenges remain in efficient training, sampling, alignment, strong generalization, and more.
- Today’s visual generation can exceed human perceptual limits—how do we properly evaluate it?
References
Contact: bili_sakura@zju.edu.cn