About this keynote: This post summarizes a slide deck on the evolution of visual generative foundation models, with emphasis on diffusion-family methods validated on ImageNet class-conditional generation.
TL;DR
Visual generation moved from convolution-heavy U-Net pipelines to transformer-first denoisers, and quality now tracks scaling behavior (data, compute, and architecture) more predictably than handcrafted tricks. Latent diffusion made high-resolution generation practical; DiT and its descendants made scaling cleaner; and recent methods such as NiT show that native-resolution training/inference can outperform fixed-resolution pipelines under similar compute budgets.
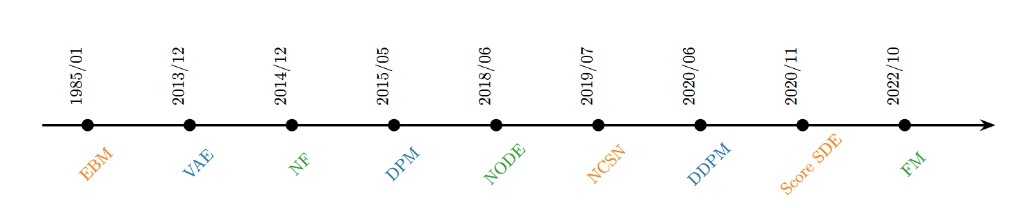
Generative Model Family
The broad landscape of deep generative modeling includes auto-regressive models, variational methods, GANs, and diffusion/score/flow families. In this keynote, the scope is intentionally narrower: diffusion-style generative foundation models for visual synthesis, primarily benchmarked on ImageNet.
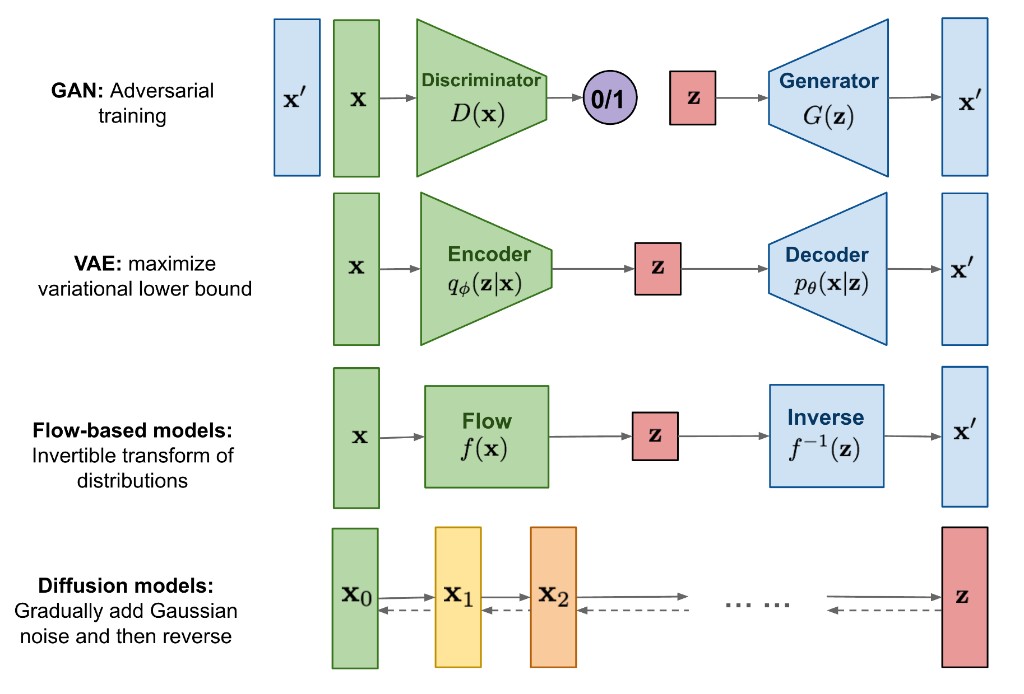
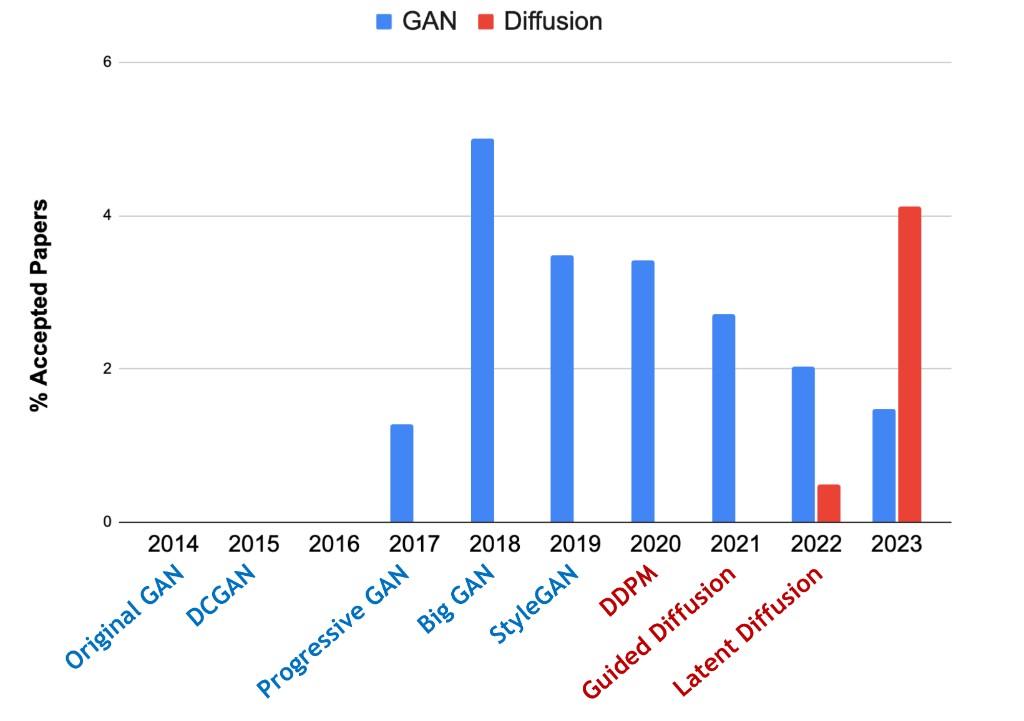
Two empirical signals motivate this focus:
- The research community shifted from GAN-dominant generation to diffusion-dominant generation.
- A practical “universal pipeline” emerged around diffusion-style noising/denoising and conditioning.
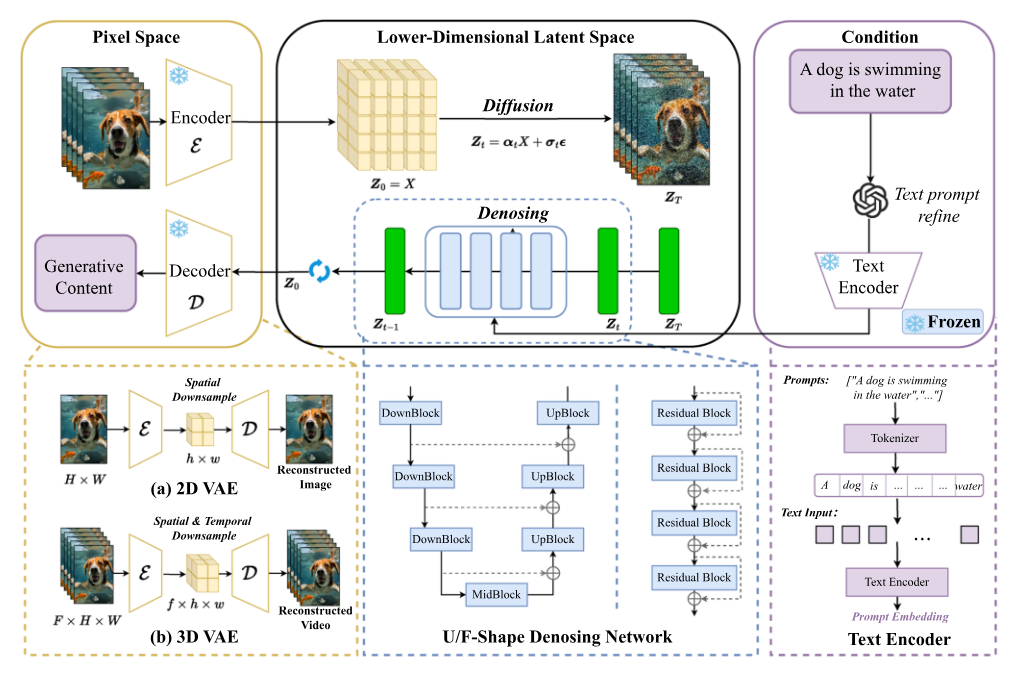
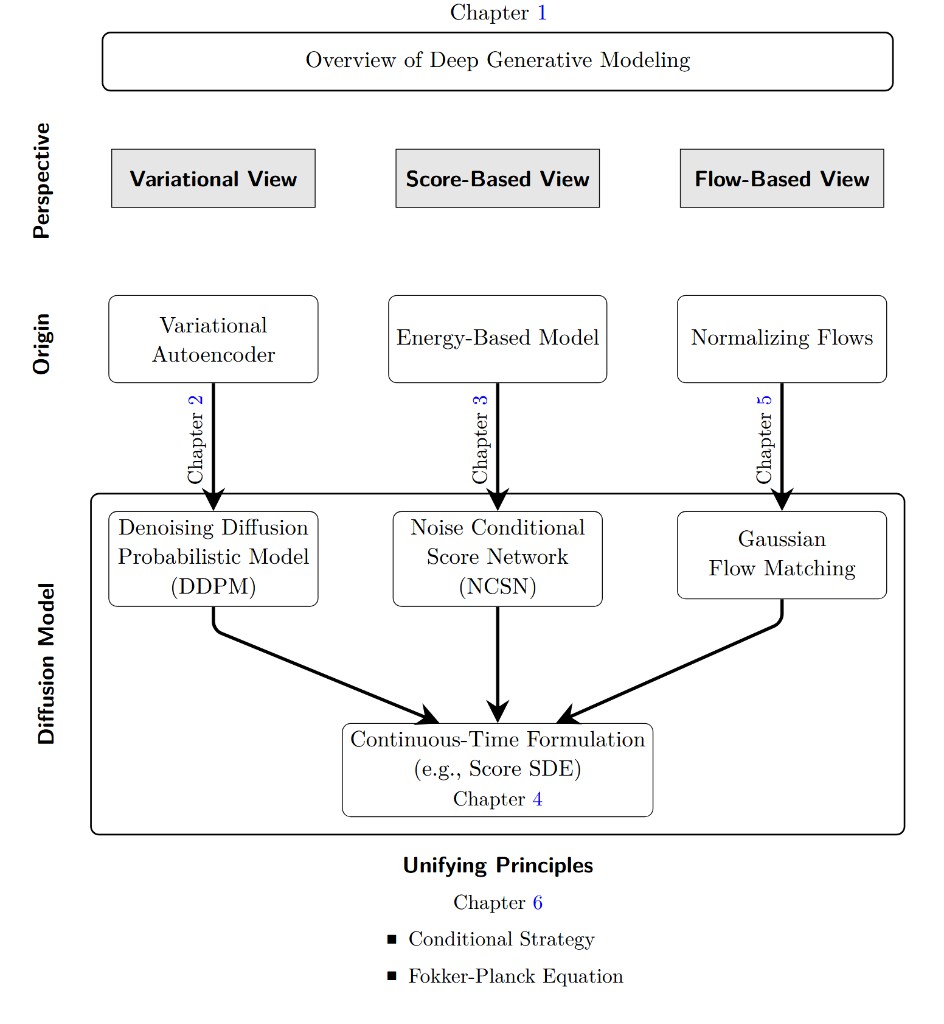
Latent Generative Foundation Models
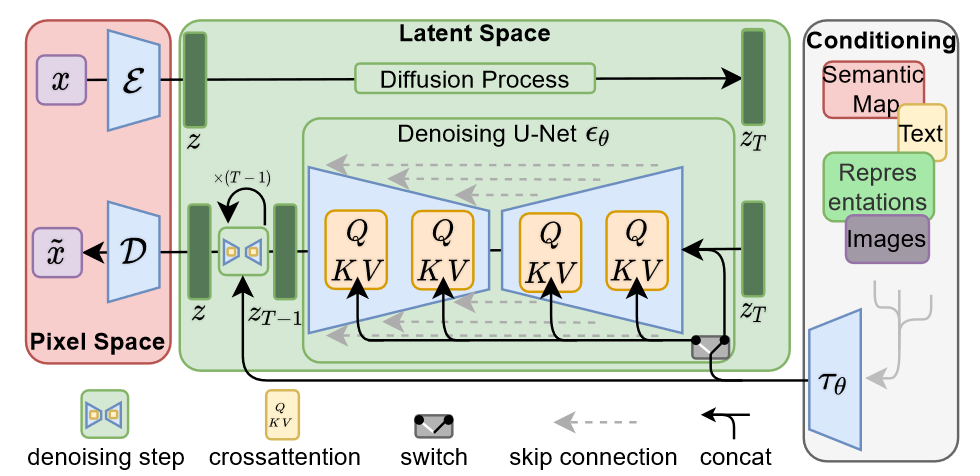
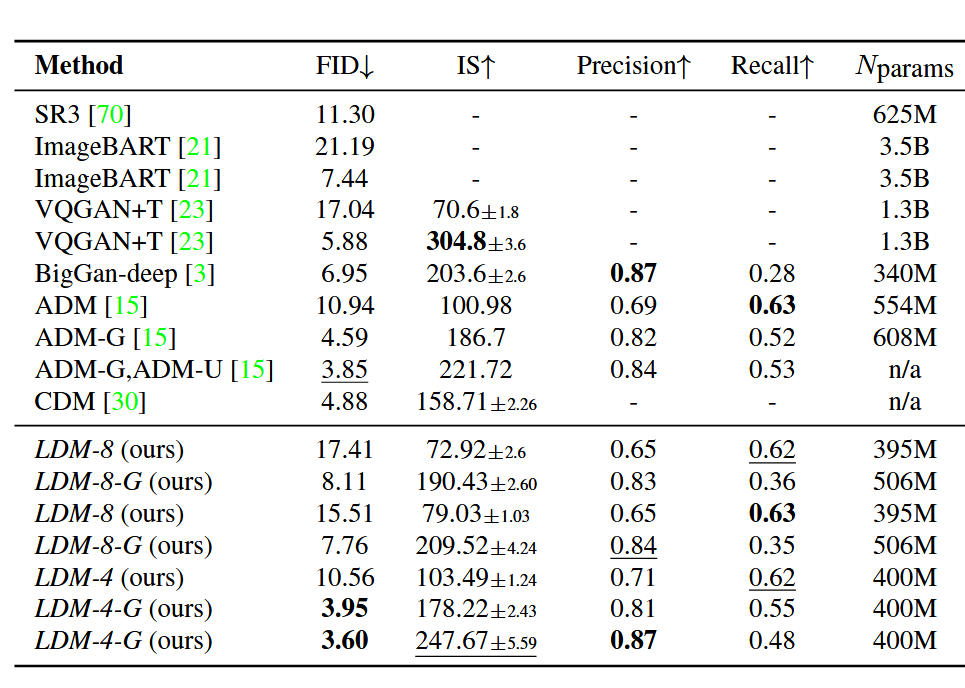
Latent Diffusion Models (LDM)
LDM introduced a crucial systems idea: run diffusion in compressed latent space instead of pixel space, then decode back to image space. This reduces compute while preserving visual quality, enabling practical high-resolution synthesis.
Diffusion Transformer (DiT)
DiT replaced the U-Net denoiser with a transformer backbone and used adaptive normalization for condition injection. This change unlocked smoother scaling with model size and training compute.
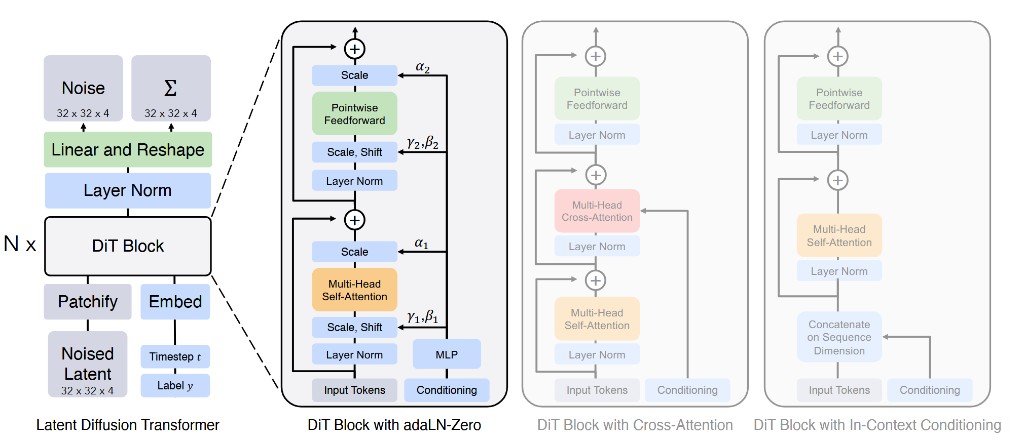
DiT’s key insight is not only architecture swap, but scale behavior: quality correlates strongly with forward-pass FLOPs.
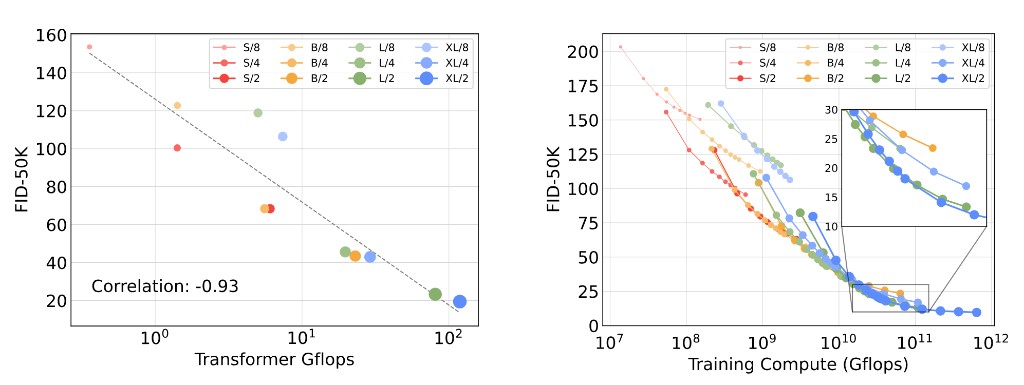

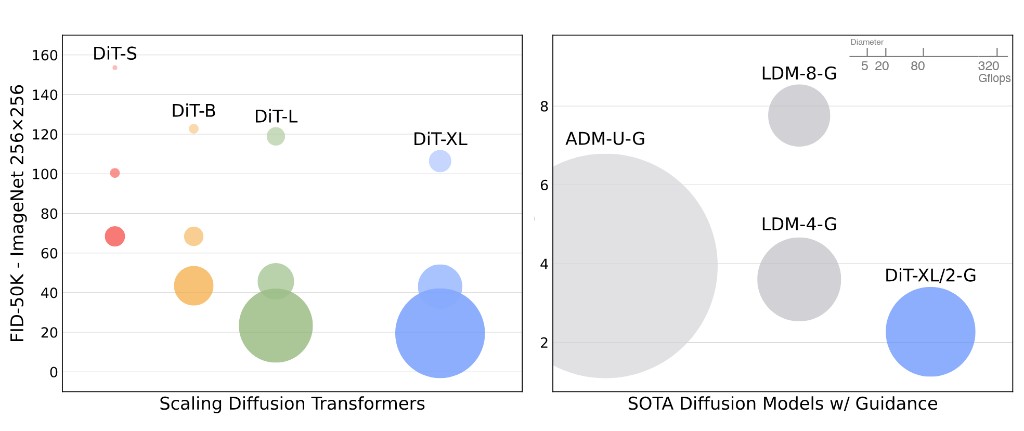
SiT: Interpolant-Based Scaling
Scalable Interpolant Transformers (SiT) keep a DiT-like backbone but reframe training under stochastic interpolants, unifying diffusion and flow perspectives. At matched scales, SiT variants improve FID over corresponding DiT baselines.

FiT and FiTv2: Flexible Resolution Transformers
FiT extends transformer diffusion to flexible aspect ratios and resolutions without retraining separate models per fixed size. The recipe combines flexible tokenization, padded or masked attention strategies, and robust positional encoding choices.
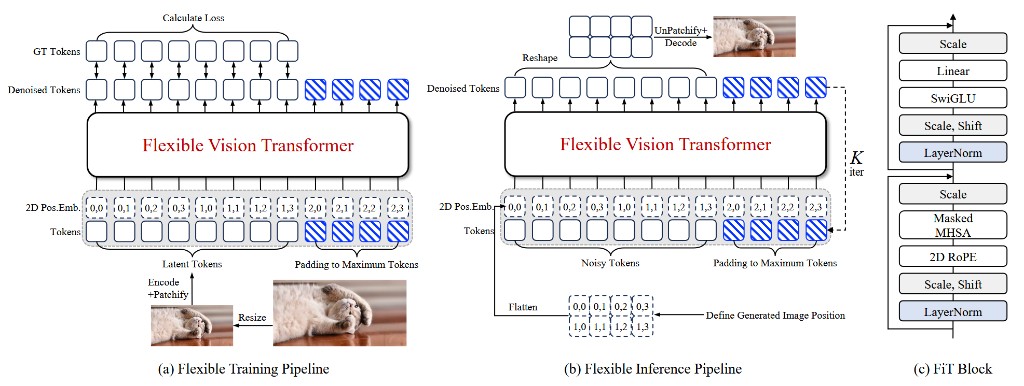
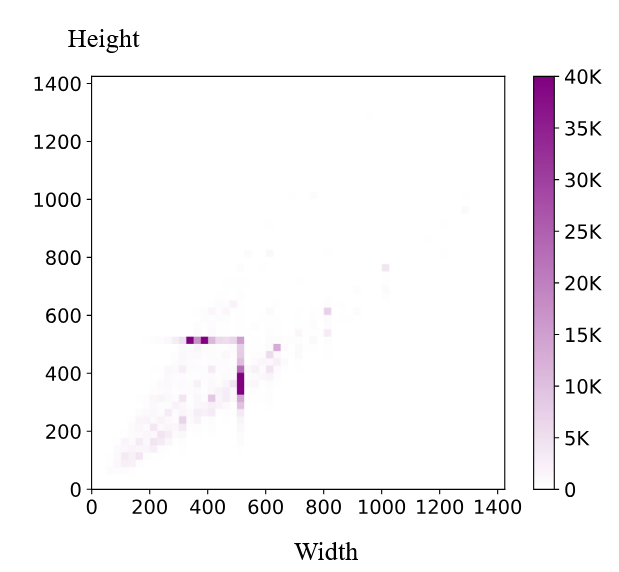
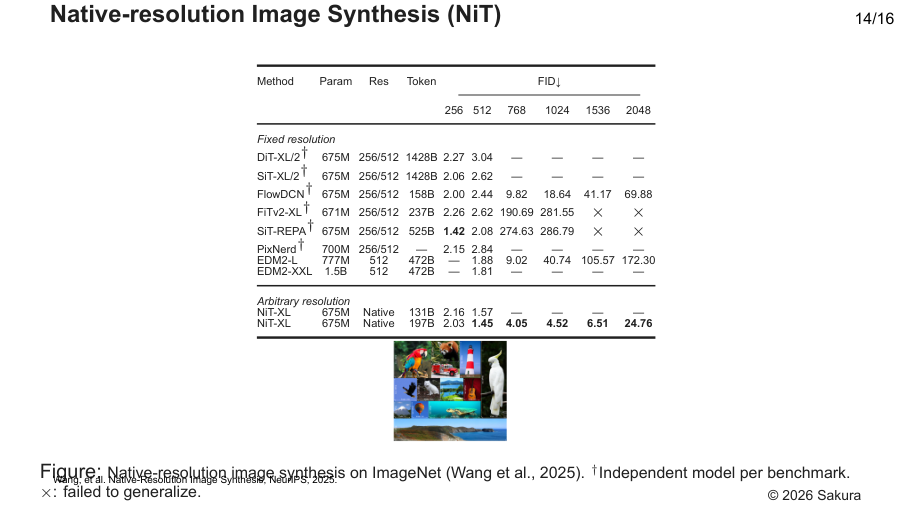
NiT: Native-Resolution Image Synthesis
NiT pushes beyond padded flexible-resolution setups: it processes native, heterogeneous token lengths directly. This reduces waste from padding and improves quality at high, non-square, or long-tail resolutions.
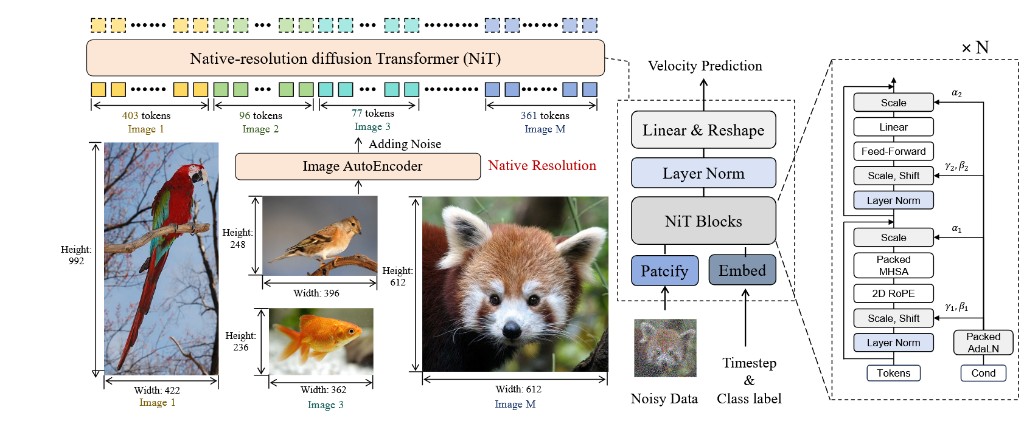

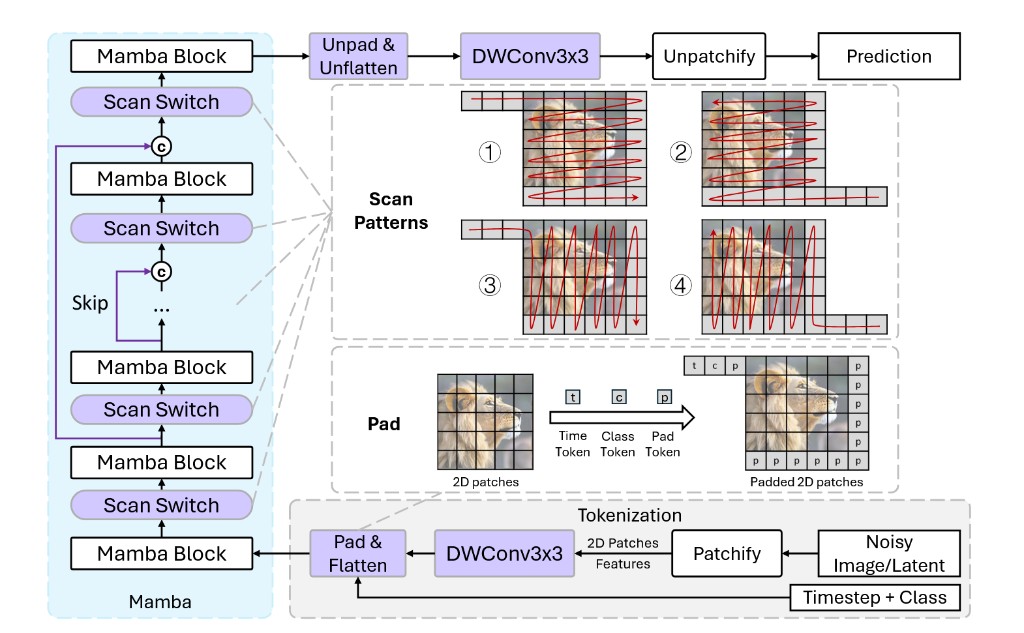
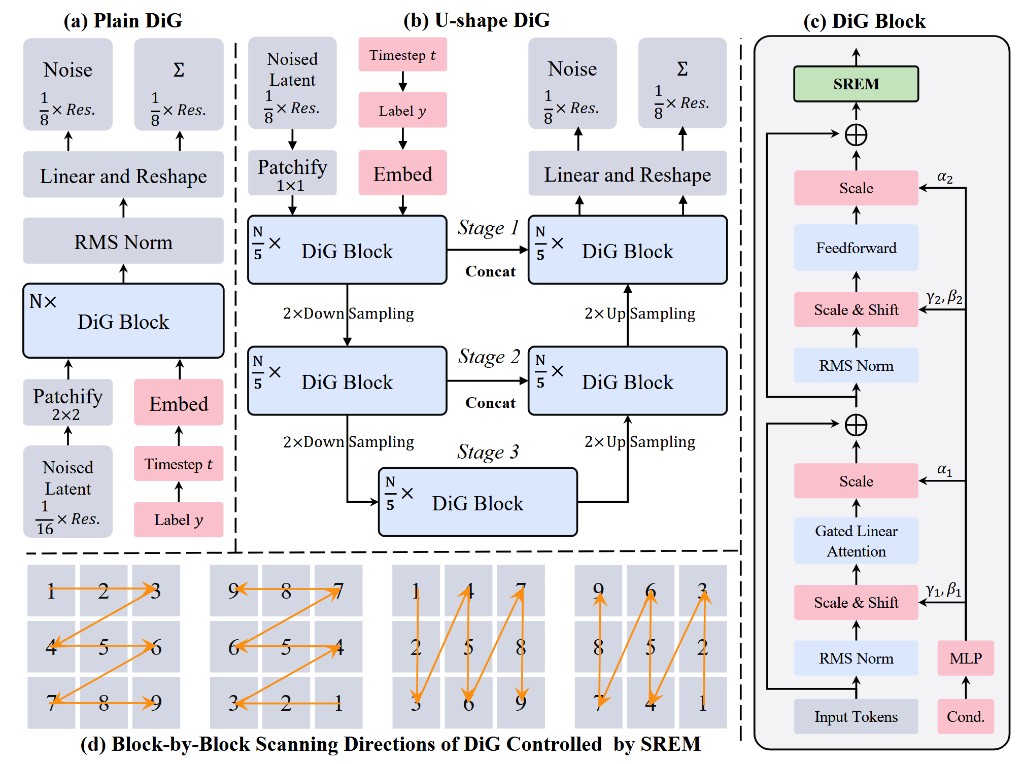
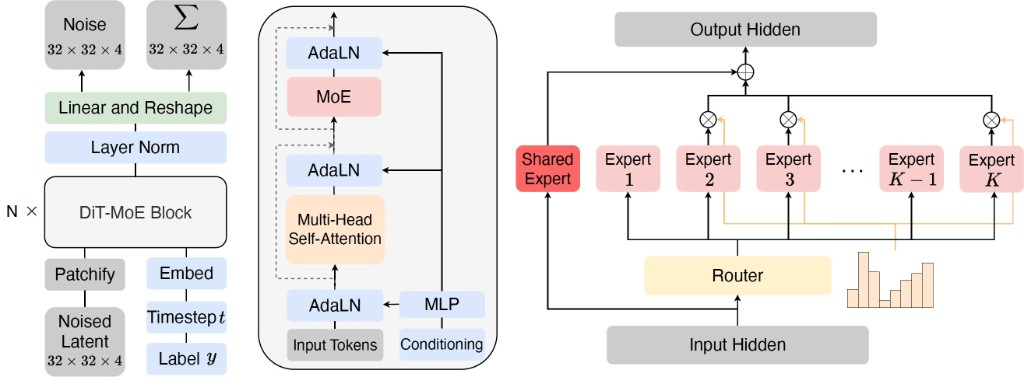
Beyond Standard Attention: DiM, DiG, and DiT-MoE
Current work also explores alternative backbone primitives and scaling strategies:
- DiM and DiG study state-space and gated-linear-attention style backbones for efficiency.
- DiT-MoE uses sparse mixture-of-experts blocks to scale parameter count aggressively while managing active compute.
Pixel Generative Foundation Models
Pixel-space generative foundation models are undergoing a renewed wave of progress, but this keynote version focuses on latent-first and latent-tokenized transformer lines. A complete pixel-space chapter (e.g., end-to-end pixel DiT variants) is planned as a follow-up update.
Takeaways
- Latent modeling was the practical bridge from academic diffusion to large-scale generative foundation models.
- Transformer denoisers are now the dominant scaling path because they map cleanly to modern compute and long-range modeling.
- Resolution flexibility is a first-class requirement: FiT/FiTv2 and especially NiT show gains from handling native aspect ratios and token lengths.
- The design space is expanding beyond dense self-attention, including interpolant formulations, linear/gated attention, SSM-style blocks, and MoE scaling.
- Future competition is likely about efficiency-quality trade-offs at scale, not only absolute benchmark wins.