Note: For the latest version of this blog post, please see https://iclr-blogposts.github.io/2026/blog/2026/diffusion-architecture-evolution/

TL;DR
As diffusion systems scale, the biggest wins tend to come from leveraging compute with broad, general methods rather than hand-crafting ever more specific tricks [1]. At the same time, we should keep sight of the “hardware lottery”: what succeeds can reflect today’s accelerators and tooling as much as inherent merit [2].
Preliminaries: Diffusion Models for Image Generation
Diffusion models have emerged as a powerful paradigm for generative modeling by learning to reverse a gradual noise corruption process. The fundamental approach involves two key stages: a forward diffusion process that systematically adds noise to data until it becomes pure Gaussian noise, and a reverse denoising process where a neural network gradually removes this noise to generate new samples.
This framework has demonstrated remarkable success across diverse domains including image generation, audio synthesis, video generation, and even applications in natural language processing and molecular design. The generality of the diffusion framework makes it particularly attractive for complex generative tasks.
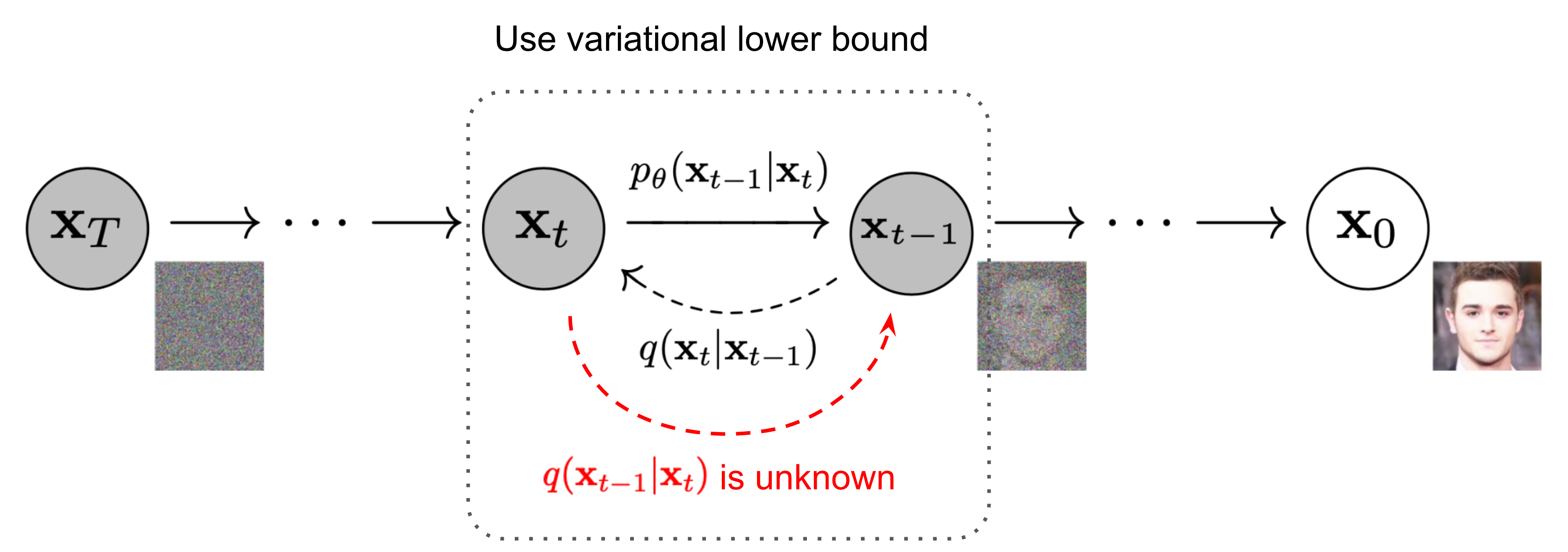
For readers seeking a comprehensive introduction to diffusion model fundamentals, we recommend Yang Song’s excellent exposition on score-based generative modeling [4] and Lilian Weng’s detailed overview of diffusion models [3].
Interactive Timeline
The U-Net Era
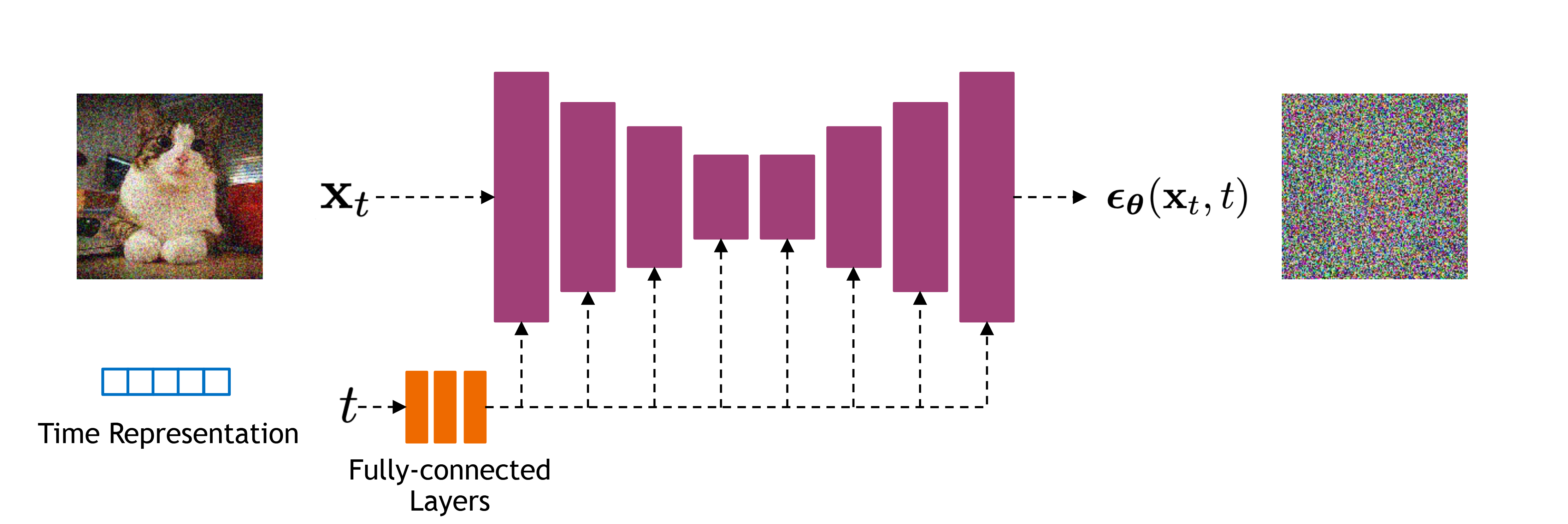
The early pioneering works in diffusion-based image generation predominantly adopted U-Net architectures [5] as their neural network backbone. This choice was largely influenced by U-Net’s proven success in various computer vision tasks [6][7].
The foundational models in this era established the core principles of diffusion-based generation. NCSN (Noise Conditional Score Network) [4] pioneered score-based generative modeling using a RefineNet backbone [6], while DDPM (Denoising Diffusion Probabilistic Models) [8] established the probabilistic framework using a PixelCNN++ architecture [7]. Subsequent refinements including NCSNv2 [9], IDDPM [10], ADM (Ablated Diffusion Model) [11], and SDE (Score-based Diffusion via Stochastic Differential Equations) [12] built upon these foundations with architectural variations similar to DDPM or NCSN. However, these early models focused primarily on unconditional image generation and lacked text-to-image capabilities.
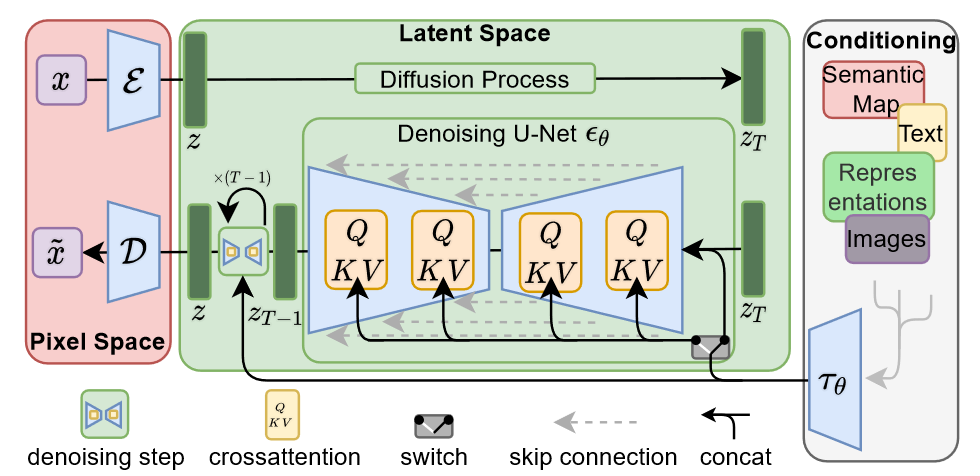
The breakthrough for text-to-image generation came with LDM (Latent Diffusion Models, also known as Stable Diffusion) [13], which introduced a latent U-Net architecture combined with a KL-regularized VAE (autoencoder) to enable efficient text-conditioned generation. Following this success, several notable U-Net-based text-to-image models emerged, each exploring different architectural innovations within the U-Net paradigm:
| Model | Gen. (#Param) | Txt. (#Param) | Total (#Param) | Release Date |
|---|---|---|---|---|
| SD v2.1 [13] | 0.87B | 0.34B | 1.29B | 2022-12-07 |
| Kandinsky [14] | 1.23B | 0.56B | 1.86B | 2023-01-01 |
| UniDiffuser [15] | 0.95B | 0.12B | 1.25B | 2023-05-12 |
| SDXL [16] | 2.57B | 0.82B | 3.47B | 2023-06-25 |
| Kandinsky 3 [17][18] | 3.06B | 8.72B | 12.05B | 2023-12-11 |
| Stable Cascade (Würstchen) [19] | 1.56B | 0.69B | 2.28B | 2024-02-07 |
The standard U-Net architecture for diffusion models typically consists of an encoder that progressively downsamples the noisy input, a bottleneck middle block that processes compressed representations, and a decoder that upsamples back to the original resolution. Crucially, skip connections preserve fine-grained spatial information across corresponding encoder and decoder stages.
Non-text conditioning: two-stage cascades and U‑ViT
Beyond text conditioning, U-Net backbones evolved substantially in non-text settings (unconditional or class-conditional), focusing on sample quality, stability, and compute efficiency:
- Two-stage/cascaded U-Nets: Decompose generation into a low-resolution base diffusion model and one or more super-resolution diffusion upsamplers. The base model captures global structure; specialized upsamplers (e.g., SR3) iteratively refine detail at higher resolutions. This cascade improves fidelity and stability on ImageNet and face datasets while keeping training tractable [21][22].
- U‑ViT (ViT backbone in a U‑shaped design): Replace CNN residual blocks with Vision Transformer blocks while retaining long-range skip connections. U‑ViT tokenizes noisy image patches, timesteps, and (optionally) class tokens, enabling stronger global context modeling than CNN U‑Nets and achieving competitive ImageNet FID with comparable compute [23].
Key takeaways (non-text U-Net family)
- Cascades separate global structure (base) from high-frequency detail (super‑res), scaling quality to high resolutions efficiently.
- ViT backbones in U‑shaped layouts preserve inductive benefits of skip connections while capturing long-range dependencies.
- These ideas later influenced text-to-image systems (e.g., two‑stage SDXL) even as the field transitioned toward DiT backbones.
The DiTs Era
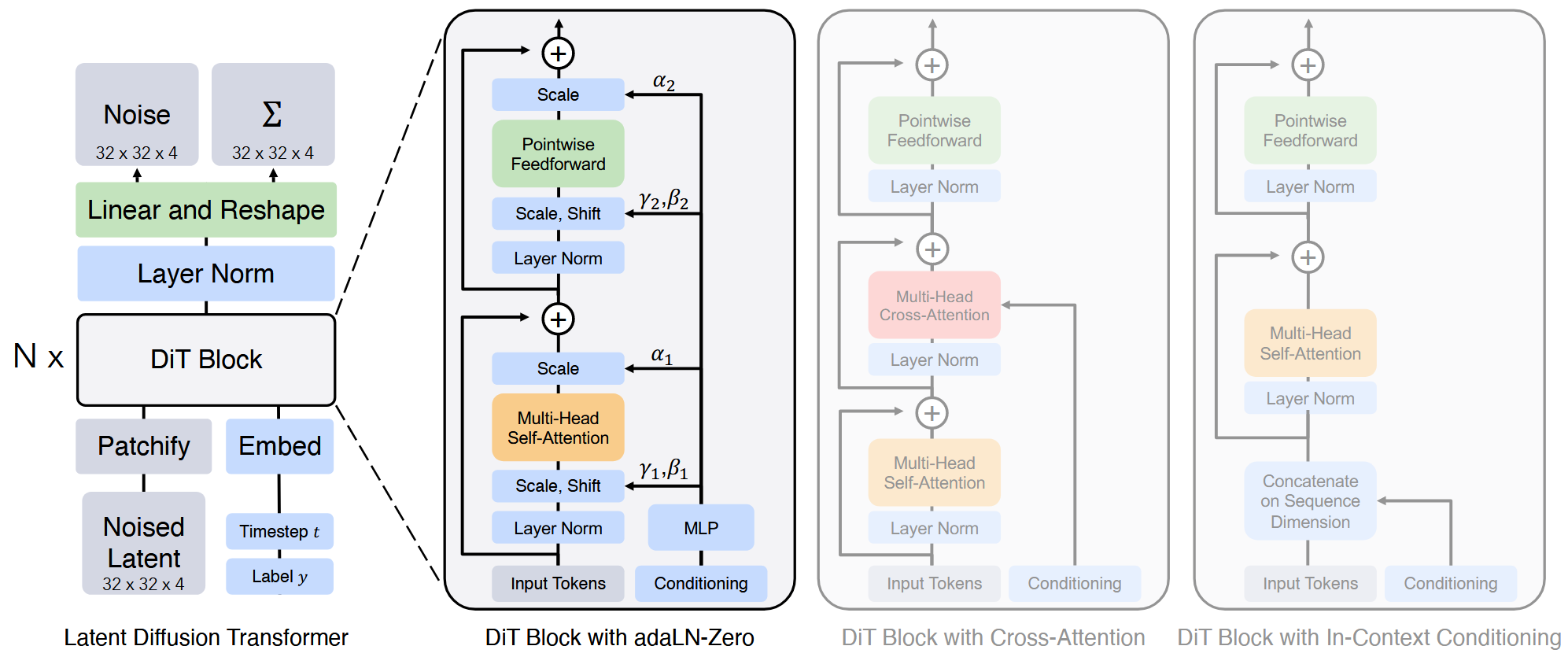
As U-Net–based models began to hit a scaling ceiling (e.g., SDXL with ~2.6B parameters [16]), naive scaling proved ineffective, motivating a shift towards alternative backbones. The introduction of Diffusion Transformers (DiTs) [24] marks a significant paradigm shift by recasting image generation as a patch-sequence modeling problem solved with transformer blocks. This approach offers several key advantages over U-Nets, including superior scalability via stacked DiT blocks, the ability to capture global context via self-attention for long-range dependencies, and a unified architecture that leverages advances in multimodal integration.
| Model | Gen. (#Param) | Txt. (#Param) | Total (#Param) | Release Date |
|---|---|---|---|---|
| PixArt-$\alpha$ [25] | 0.61B | 4.76B | 5.46B | 2023/10/06 |
| Lumina-T2I [26] | ~4.7B | ~7B | ~15B | 2024/04/01 |
| PixArt-$\Sigma$ [27] | 0.61B | 4.76B | 5.46B | 2024/04/11 |
| Lumina-Next-T2I [28] | 1.75B | 2.51B | 4.34B | 2024/05/12 |
| Stable Diffusion 3 [29] | 2.03B | 5.58B | 7.69B | 2024/06/12 |
| Flux.1-Dev [30] | 11.90B | 4.88B | 16.87B | 2024/08/02 |
| CogView3-Plus [31] | 2.85B | 4.76B | 8.02B | 2024/10/13 |
| Hunyuan-DiT [32] | 1.50B | 2.02B | 3.61B | 2024/12/01 |
| SANA [33] | 0.59B | 2.61B | 3.52B | 2025/01/11 |
| Lumina-Image 2.0 [34] | 2.61B | 2.61B | 5.31B | 2025/01/22 |
| SANA 1.5 [35] | 1.60B | 2.61B | 4.53B | 2025/03/21 |
| HiDream-I1-Dev [36] | 17.11B | 5.58B | 22.77B | 2025/04/06 |
| CogView4-6B [31] | 3.50B | 2.00B | 6.00B | 2025/05/03 |
| Qwen-Image [37] | 20.43B | 8.29B | 28.85B | 2025/08/04 |
Latest Advancement in U-Net and DiT Architecture Design
While the transition from U-Net to DiT architectures represents a major paradigm shift, both architectural families have continued to evolve with innovative refinements. In the U-Net domain, two-stage cascaded approaches [21][22] decompose generation into a low-resolution base model and specialized super-resolution upsamplers, improving fidelity while maintaining training tractability. U-ViT [23] bridges U-Net and transformer architectures by replacing CNN residual blocks with Vision Transformer blocks while retaining the characteristic U-shaped structure and skip connections, enabling stronger global context modeling with competitive ImageNet performance. Challenging the dominance of latent-space models, Simple Diffusion [72] and Simpler Diffusion (SiD2) [73] demonstrate that end-to-end pixel-space diffusion can achieve state-of-the-art performance (FID 1.48 on ImageNet 512) through optimized noise schedules and simplified architectures.
The DiT family has seen rapid advances across multiple dimensions. Architecture variants include SiT (Scalable Interpolant Transformer) [78], which replaces diffusion with interpolant-based transport for improved stability, FiT (Flexible Vision Transformer) [74] which supports unrestricted resolutions and aspect ratios, and LiT (Linear Diffusion Transformer) [33][79], which achieves O(n) complexity through linear attention mechanisms enabling higher-resolution generation, and DiG (Diffusion GLA) [75] which achieves O(n) complexity through linear attention mechanisms. Training efficiency innovations such as MDT/MDTv2 [38][39] and MaskDiT [40] leverage masked latent modeling to achieve 10× faster learning and competitive performance with only 30% of standard training time, while representation-based approaches REPA (REPresentation Alignment) [41] and REG (Representation Entanglement for Generation) [42] incorporate external pretrained visual representations to dramatically accelerate training—REPA achieves 17.5× speedup and FID of 1.42, while REG achieves 63× faster training than baseline SiT by entangling image latents with class tokens during denoising with negligible inference overhead. Architecture refinements like DDT [43] decouple semantic encoding from high-frequency decoding for 4× faster convergence. In parallel, U-DiTs downsample (and later upsample) tokens in a U-shaped DiT, shortening the effective sequence length to reduce attention cost while preserving fine detail for high-resolution synthesis [44]. Furthermore, JiT (“Just image Transformers”) [76][77] revisits the basics, showing that plain transformers operating directly on pixels or patches can perform surprisingly well without complex tokenizers. Meanwhile, tokenizer innovations leverage pretrained foundation models: RAE [45] replaces standard VAEs with pretrained representation encoders (DINO, SigLIP, MAE) achieving FID of 1.13, and Aligned Visual Foundation Encoders [46] employ a three-stage alignment strategy to transform foundation encoders into semantically rich tokenizers, accelerating convergence (gFID 1.90 in 64 epochs) and outperforming standard VAEs in text-to-image generation.
Pre-trained Text-to-Image Checkpoints
The landscape of pre-trained text-to-image models has evolved dramatically since the introduction of Stable Diffusion. These models serve as powerful foundation models that can be adapted for specialized downstream tasks without architectural modifications, simply by fine-tuning on domain-specific datasets.
Interactive Architecture Explorer
U-Net Family
Stable Diffusion [13] represents the pioneering work in latent diffusion models, adopting a U-Net architecture that operates in a compressed latent space rather than pixel space. This design choice dramatically reduces computational costs while maintaining high-quality generation capabilities. The model combines two key components: a pre-trained variational autoencoder (VAE) for efficient image compression and decompression, and a diffusion model that performs the denoising process in this latent space.1
Stable Diffusion XL (SDXL) [16] marked a significant scaling advancement, adopting a two-stage U-Net architecture and increasing the model size from 0.8 billion to 2.6 billion parameters. SDXL remains one of the largest U-Net-based models for image generation and demonstrates improved efficiency and compatibility across diverse domains and tasks. Despite reaching scaling limits, SDXL continues to serve as a foundation for numerous specialized applications.
Kandinsky [14] represents a significant advancement in the U-Net era, introducing a novel exploration of latent diffusion architecture that combines image prior models with latent diffusion techniques. The model features a modified MoVQ implementation as the image autoencoder component and achieves a FID score of 8.03 on the COCO-30K dataset, marking it as the top open-source performer in terms of measurable image generation quality. Kandinsky 3 [17][18] continues this series with improved text understanding and domain-specific performance, presenting a multifunctional generative framework supporting text-guided inpainting/outpainting, image fusion, and image-to-video generation.
Stable Cascade (based on Würstchen architecture) [19] introduces an efficient architecture for large-scale text-to-image diffusion models, achieving competitive performance with unprecedented cost-effectiveness. The key innovation is a latent diffusion technique that learns extremely compact semantic image representations, reducing computational requirements significantly—training requires only 24,602 A100-GPU hours compared to Stable Diffusion 2.1’s 200,000 GPU hours while maintaining state-of-the-art results.
UniDiffuser [15] explores transformer-based diffusion models with a unified framework that fits all distributions relevant to multi-modal data in one model. While primarily focused on transformer architectures, this work demonstrates the potential for unified multi-modal generation within the diffusion framework.
PixArt-$\alpha$ (2023/10/06)
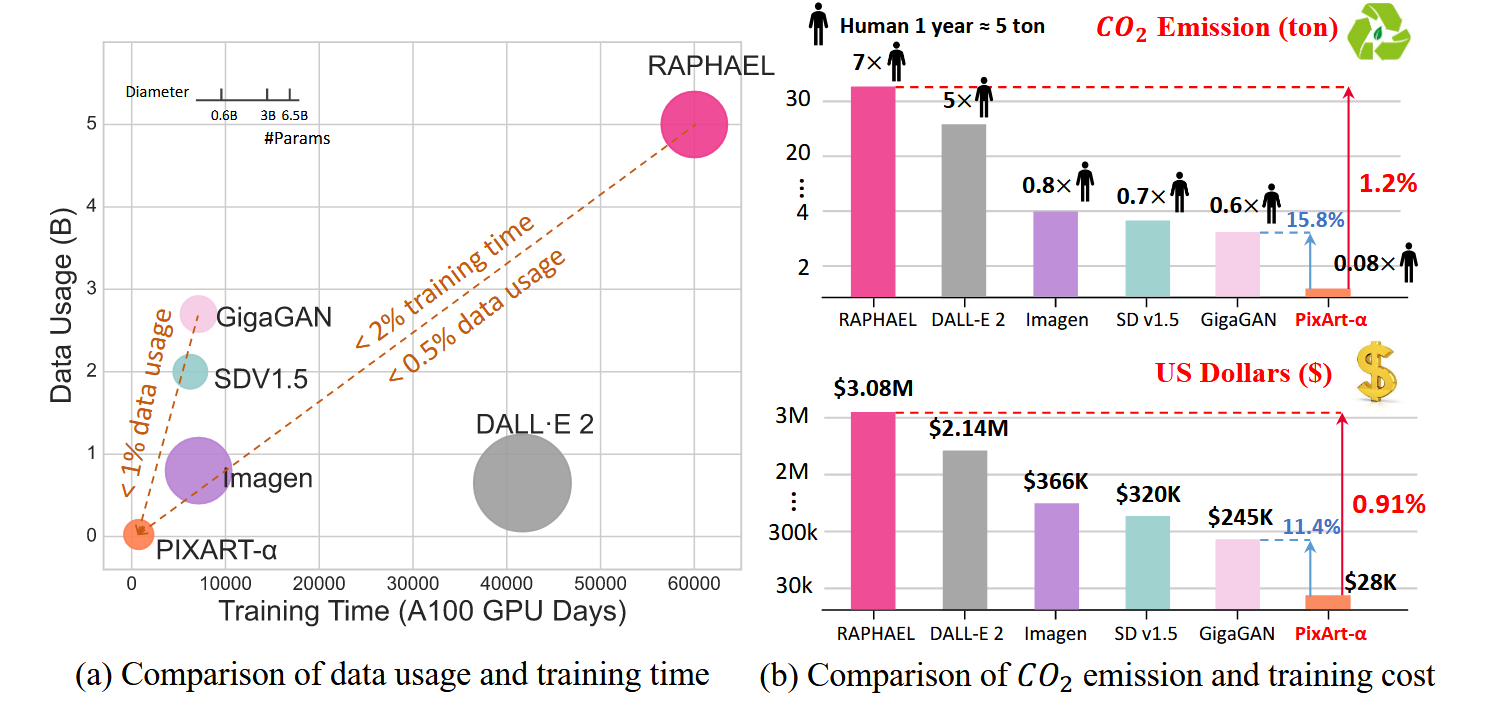
PixArt-$\alpha$ is motivated by the rising compute and environmental costs of text-to-image systems, seeking near-commercial quality with a much smaller training budget [25]. In contrast to SD 1.5/2.1, it adopts a large-language-model text encoder (T5) [48], making it the first open-source diffusion T2I model to use an LLM-based text encoder while keeping the overall design streamlined.
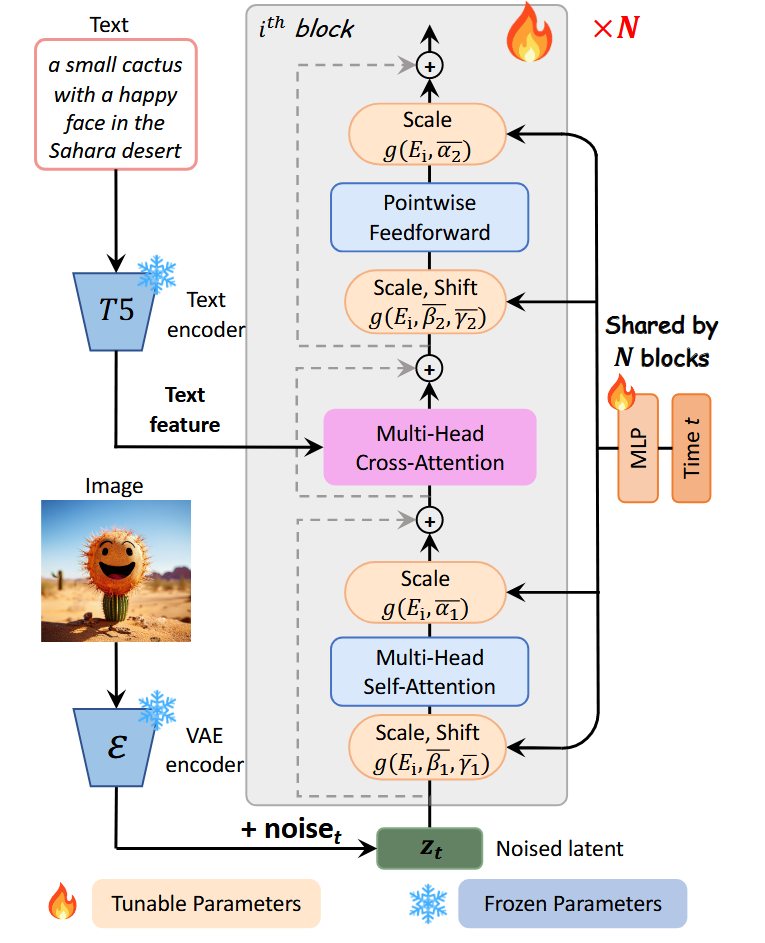
Architecturally, PixArt-$\alpha$ is a latent Diffusion Transformer (DiT): VAE latents are patchified into a token sequence processed by stacked Transformer blocks; each block applies cross-attention to text tokens, and timestep conditioning is injected via a shared adaLN-single, simplifying parameters and conditioning pathways [25].
- Transformer sequence-of-patches backbone (no encoder–decoder or skip connections)
- Shared adaLN for time and unified per-block cross-attention (vs U-Net residual blocks with per-block time MLP/spatial injections)
- T5 text encoder (LLM) rather than CLIP/OpenCLIP
Lumina-T2I (2024/04/01)
Lumina-T2I is the first entry in the Lumina series from Shanghai AI Lab, aiming for a simple, scalable framework that supports flexible resolutions while maintaining photorealism. Building on the Sora insight that scaling Diffusion Transformers enables generation across arbitrary aspect ratios and durations yet lacks concrete implementation details, Lumina-T2I adopts flow matching to stabilize and accelerate training [26].
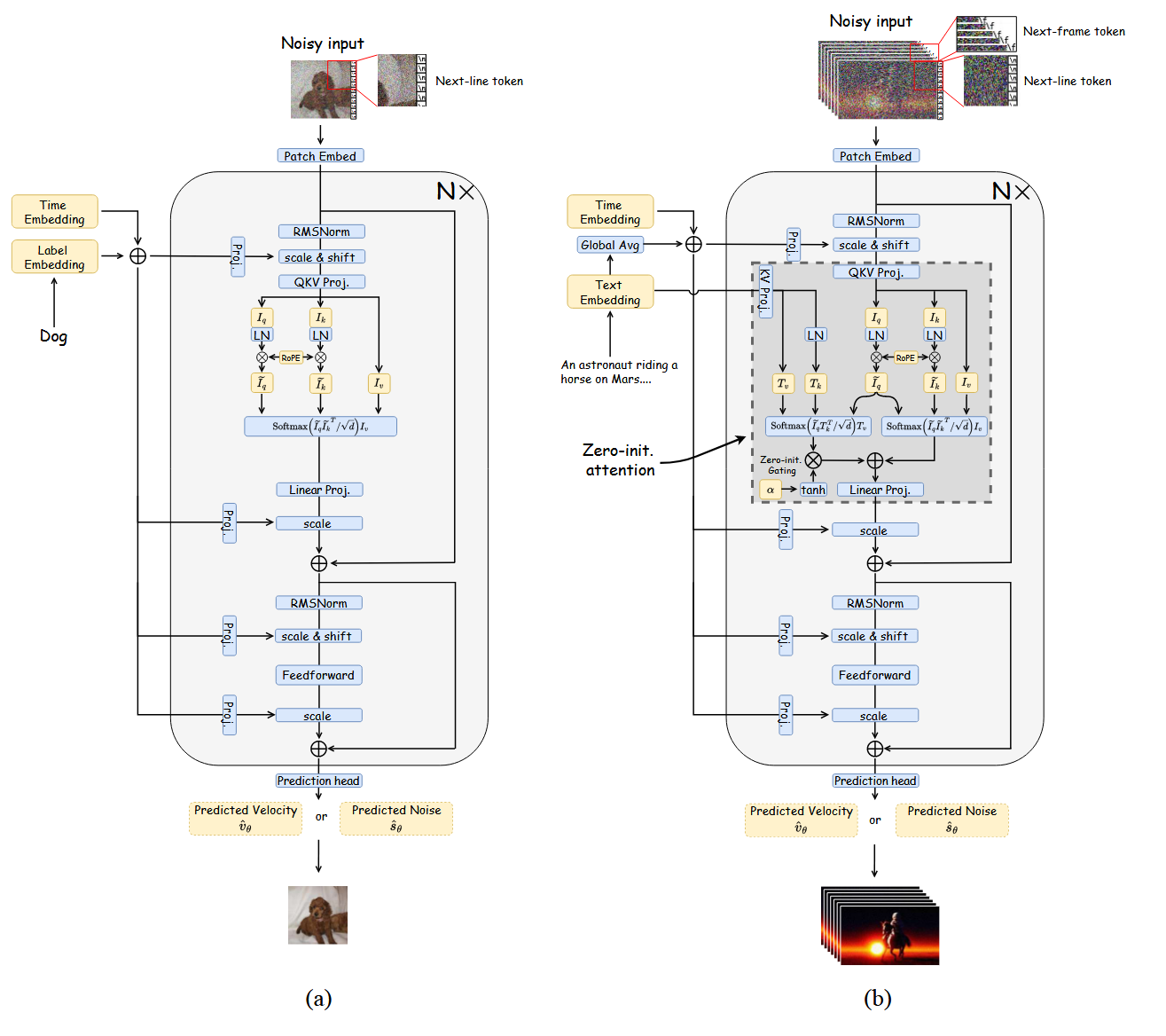
Architecturally, Lumina-T2I uses a Flow-based Large Diffusion Transformer (Flag-DiT) with zero-initialized attention, RoPE [50], and KQ-Norm [51]. Latent features are tokenized and processed by Transformer blocks; learnable placeholders such as the [nextline] token and layerwise relative position injection enable robust resolution extrapolation without retraining for each size.
- Robust resolution generalization across 512²–1792²
- Uses one-dimensional RoPE, [nextline] token, and layerwise relative position injection
- PixArt-α uses absolute positional embeddings limited to the initial layer, degrading at out-of-distribution scales
PixArt-$\Sigma$ (2024/04/11)
PixArt-$\Sigma$ achieves superior image quality and user prompt adherence capabilities with significantly smaller model size (0.6B parameters) than existing text-to-image diffusion models, such as SDXL (2.6B parameters) and SD Cascade (5.1B parameters). Moreover, PixArt-$\Sigma$’s capability to generate 4K images supports the creation of high-resolution posters and wallpapers, efficiently bolstering the production of high-quality visual content in industries such as film and gaming.
Architecturally, PixArt-$\Sigma$ maintains the same DiT backbone as PixArt-$\alpha$ but introduces efficient token compression through a novel attention module within the DiT framework that compresses both keys and values, significantly improving efficiency and facilitating ultra-high-resolution image generation. The model incorporates superior-quality image data paired with more precise and detailed image captions, along with data curriculum strategies for improved training effectiveness.
- Efficient token compression via novel attention module compressing keys and values
- Superior-quality training data with more precise and detailed captions
- Data curriculum strategies for improved training effectiveness
- 4K image generation capability for high-resolution content creation
Lumina-Next-T2I (2024/05/12)
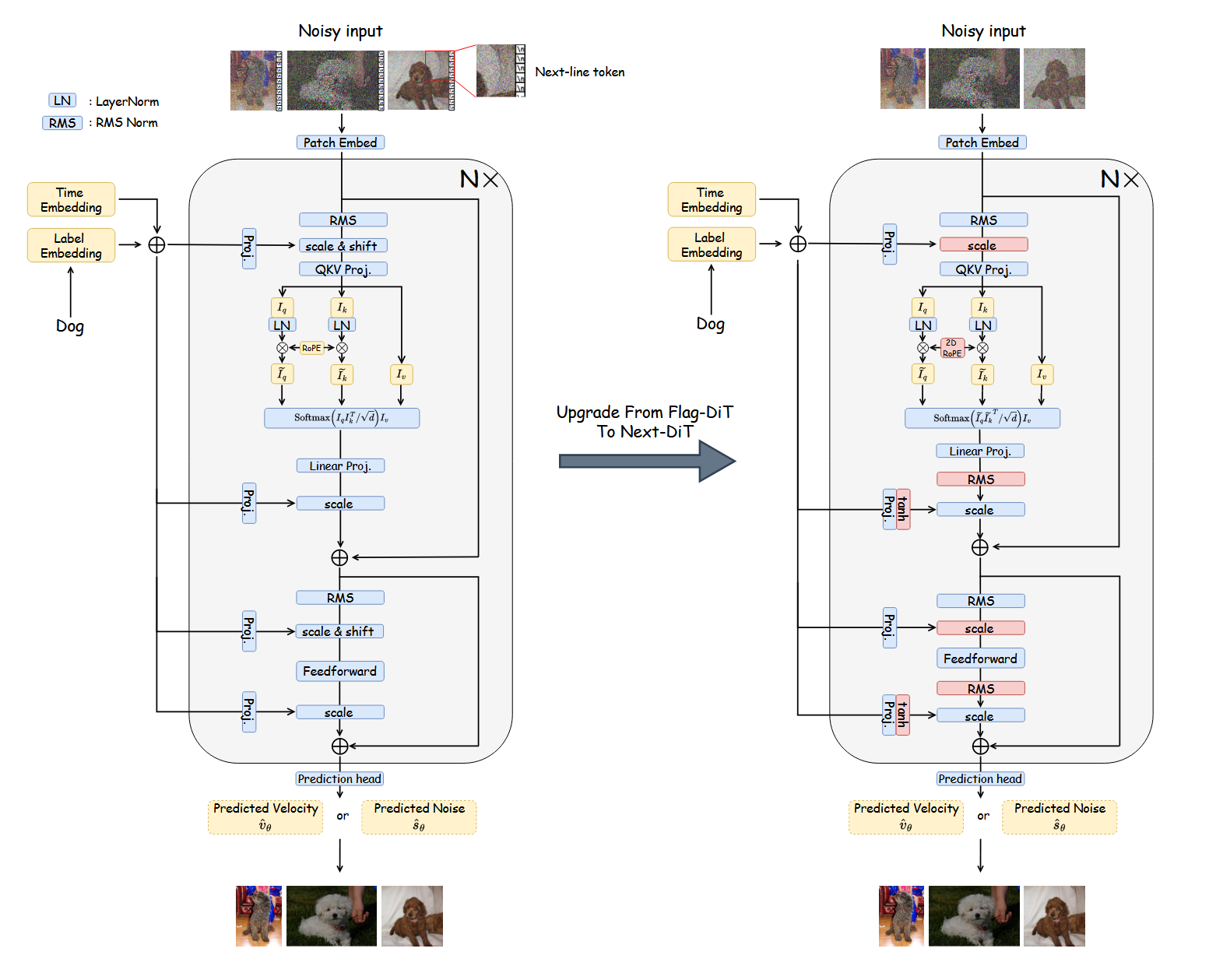
Lumina-Next-T2I [28] targets the core limitations observed in Lumina-T2X—training instability, slow inference, and resolution extrapolation artifacts—by delivering stronger quality and faster sampling while improving zero-shot multilingual understanding. Unlike prior T2I works that rely on CLIP or T5 encoders [48], the Lumina series adopts decoder-only LLMs as text encoders: Lumina-T2X uses LLaMA-2 7B [52], whereas Lumina-Next employs the lighter Gemma-2B to reduce memory and increase throughput. In practice, Lumina-Next shows clear gains on multilingual prompts (vs. CLIP/T5 setups) and further improves text-image alignment with alternative LLMs like Qwen-1.8B and InternLM-7B.
Architecturally, Lumina-Next introduces the Next-DiT backbone with 3D RoPE and Frequency- and Time-Aware Scaled RoPE for robust resolution extrapolation [50]. It adds sandwich normalizations to stabilize training (cf. normalization strategies such as KQ-Norm [51]), a sigmoid time discretization schedule to reduce Flow-ODE sampling steps, and a Context Drop mechanism that merges redundant visual tokens to accelerate inference—all while retaining the flow-based DiT formulation of the Lumina family.
- Next-DiT with 3D RoPE + frequency/time-aware scaling for stronger resolution extrapolation
- Sandwich normalizations improve stability; sigmoid time schedule reduces sampling steps
- Context Drop merges redundant tokens for faster inference throughput
- Decoder-only LLM text encoders (Gemma-2B by default; Qwen-1.8B/InternLM-7B optional) boost zero-shot multilingual alignment vs CLIP/T5
Stable Diffusion 3 (2024/06/12)
Stable Diffusion 3 aims to improve existing noise sampling techniques for training rectified flow models by biasing them towards perceptually relevant scales, demonstrating superior performance compared to established diffusion formulations for high-resolution text-to-image synthesis [29]. This work presents the first comprehensive scaling study for text-to-image DiTs, establishing predictable scaling trends and correlating lower validation loss to improved synthesis quality across various metrics and human evaluations.
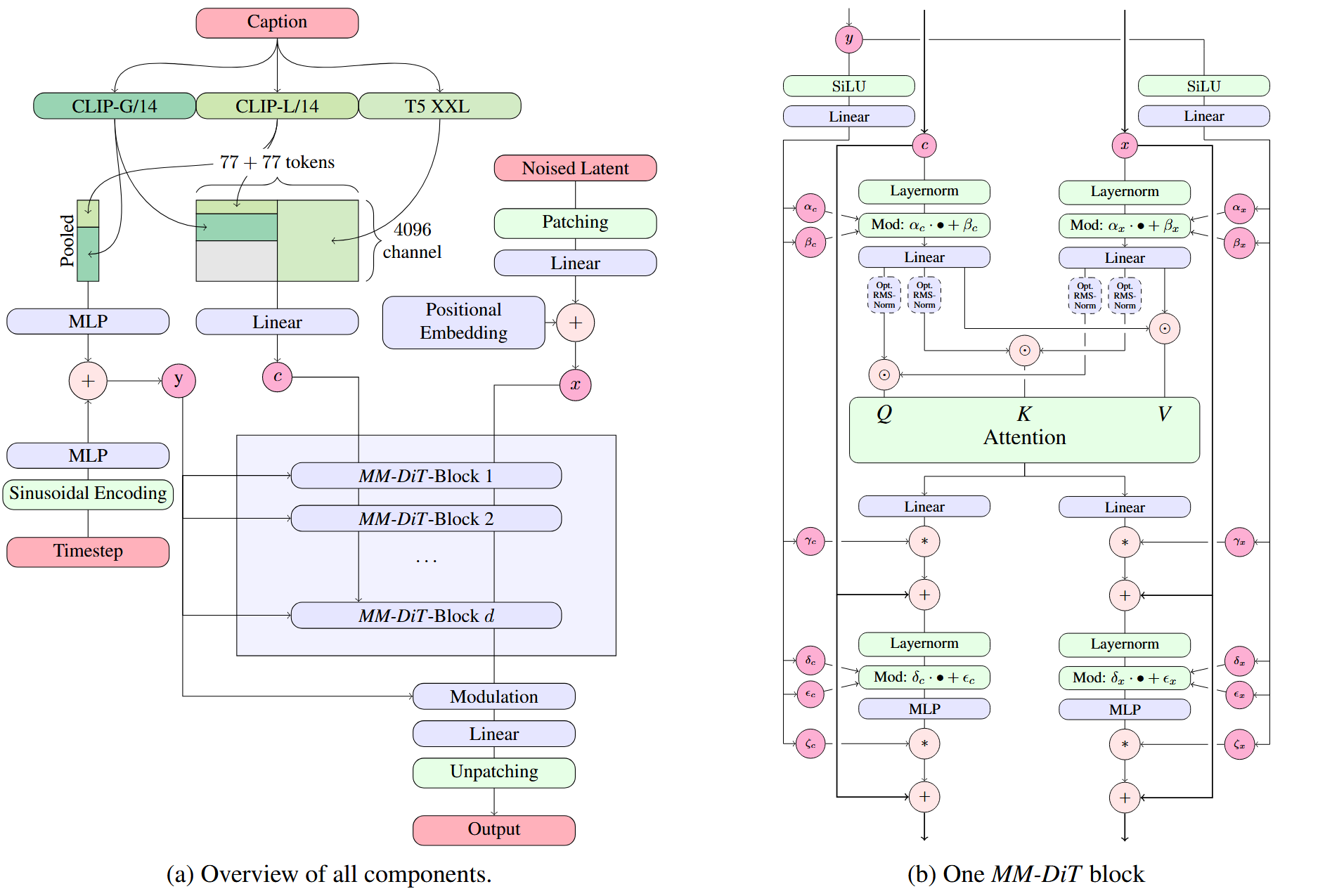
Architecturally, SD3 transitions from DiT’s cross-attention blocks to MMDiT (Multimodal Diffusion Transformer) with double-stream blocks that use separate weights for the two modalities, enabling bidirectional flow of information between image and text tokens for improved text comprehension and typography. Unlike SDXL which relies primarily on CLIP encoders, SD3 incorporates both CLIP (L/14 and OpenCLIP bigG/14) and T5-XXL encoders [48], concatenating pooled outputs and hidden representations to create comprehensive text conditioning with enhanced understanding capabilities.
- MMDiT double-stream architecture with separate weights per modality and bidirectional information flow (vs single-stream cross-attention)
- Integrated rectified flow training with perceptually-biased noise sampling (vs standard diffusion formulation)
- Combined CLIP + T5-XXL text encoding for enhanced text comprehension and typography
- First comprehensive scaling study demonstrating predictable trends for text-to-image DiTs
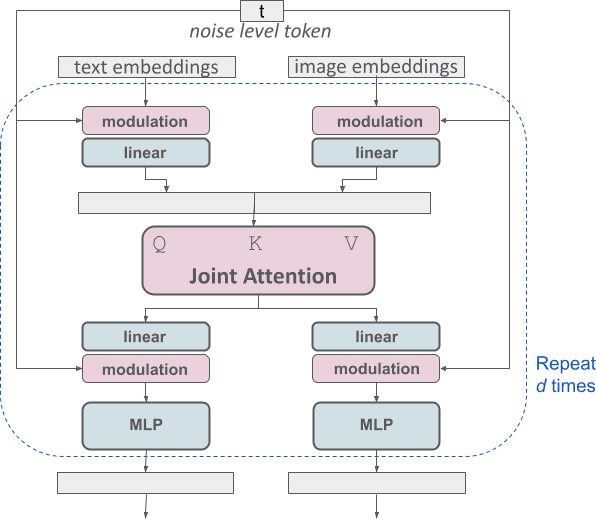
Flux.1-Dev (2024/08/02)
Flux.1-Dev, developed by former Stability AI core members, aims to scale beyond previous models and achieve superior image quality with more accurate text-to-image synthesis [30]. Representing a significant scaling effort, the model features a massive 12 billion parameter generator combined with a 4.7 billion parameter text encoder, marking substantial growth compared to predecessors and establishing new benchmarks in AI-driven image generation capabilities.
Architecturally, Flux.1-Dev advances beyond SD3’s MMDiT by implementing a hybrid architecture that combines both single-stream and double-stream Multi-Modal Diffusion Transformers, enhancing the model’s ability to process complex visual-textual relationships. Like SD3, it incorporates T5 text encoding [48] and integrates rectified flow techniques for more stable and efficient training, while conducting a comprehensive scaling study that optimizes performance across the substantially larger parameter space.
- Hybrid single-stream + double-stream MMDiT architecture (vs purely double-stream MMDiT)
- Massive scaling to 12B generator + 4.7B text encoder parameters (vs smaller SD3 variants)
- Enhanced rectified flow implementation optimized for larger scale training
- Comprehensive scaling study specifically designed for multi-billion parameter DiTs
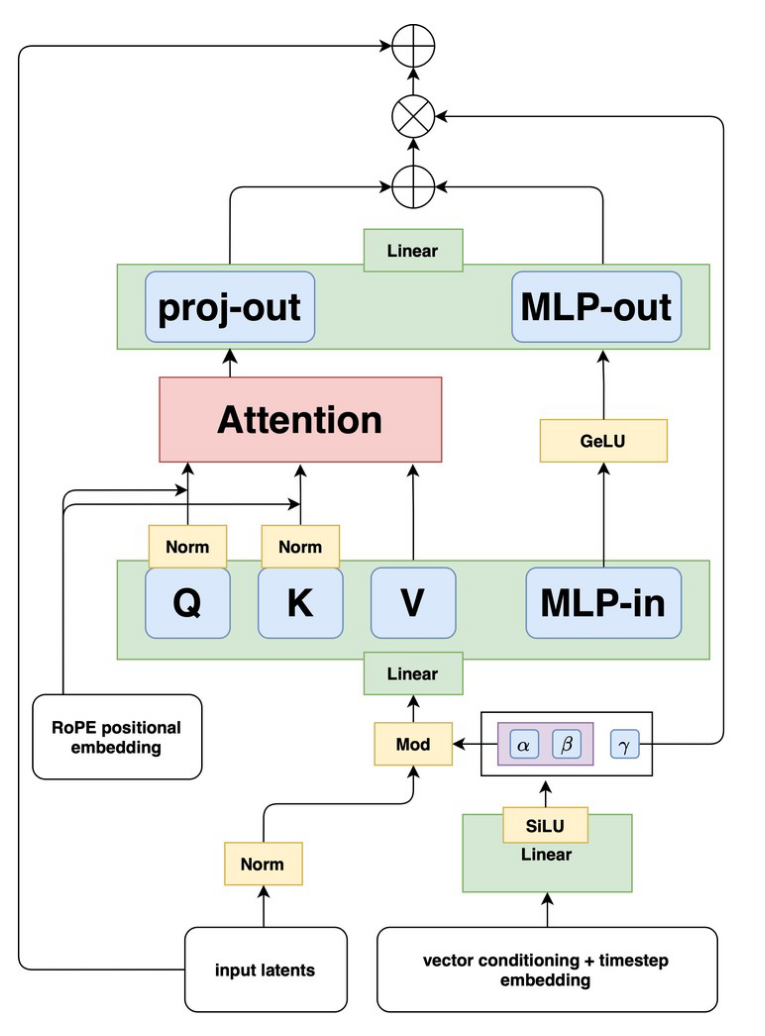
CogView3 & CogView3-Plus (2024/10/13)
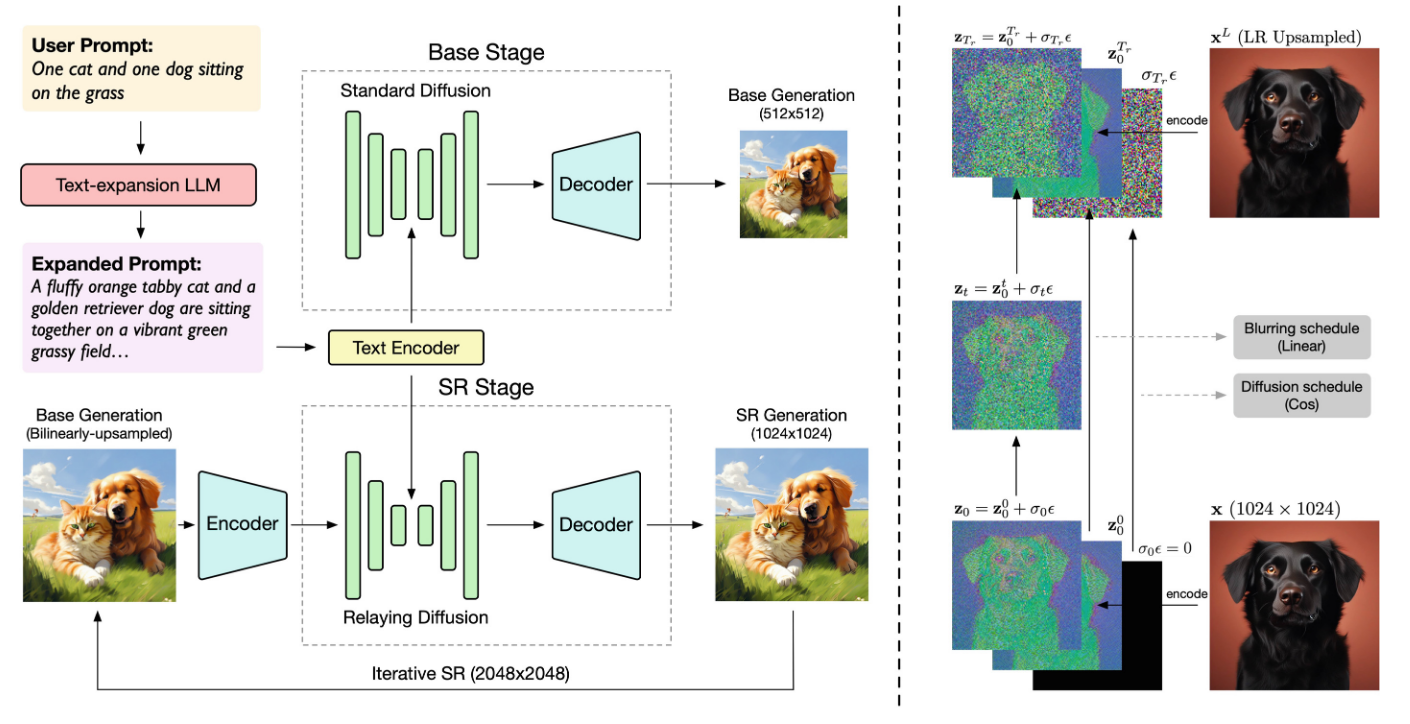
CogView3 [31] introduces a relay diffusion approach [54] that generates low-resolution images first, then refines them through super-resolution to achieve 2048×2048 outputs. This multi-stage process reduces computational costs while improving quality—CogView3 outperformed SDXL by 77% in human evaluations while using only one-tenth the inference time. The model employs a text-expansion language model to rewrite user prompts, with a base stage generating 512×512 images followed by relaying super-resolution in the latent space.
CogView3-Plus upgrades to DiT architecture with Zero-SNR scheduling and joint text-image attention for further efficiency gains. This architectural evolution represents a significant step in the CogView series, transitioning from traditional approaches to transformer-based diffusion models while maintaining the efficiency advantages of the relay diffusion framework.
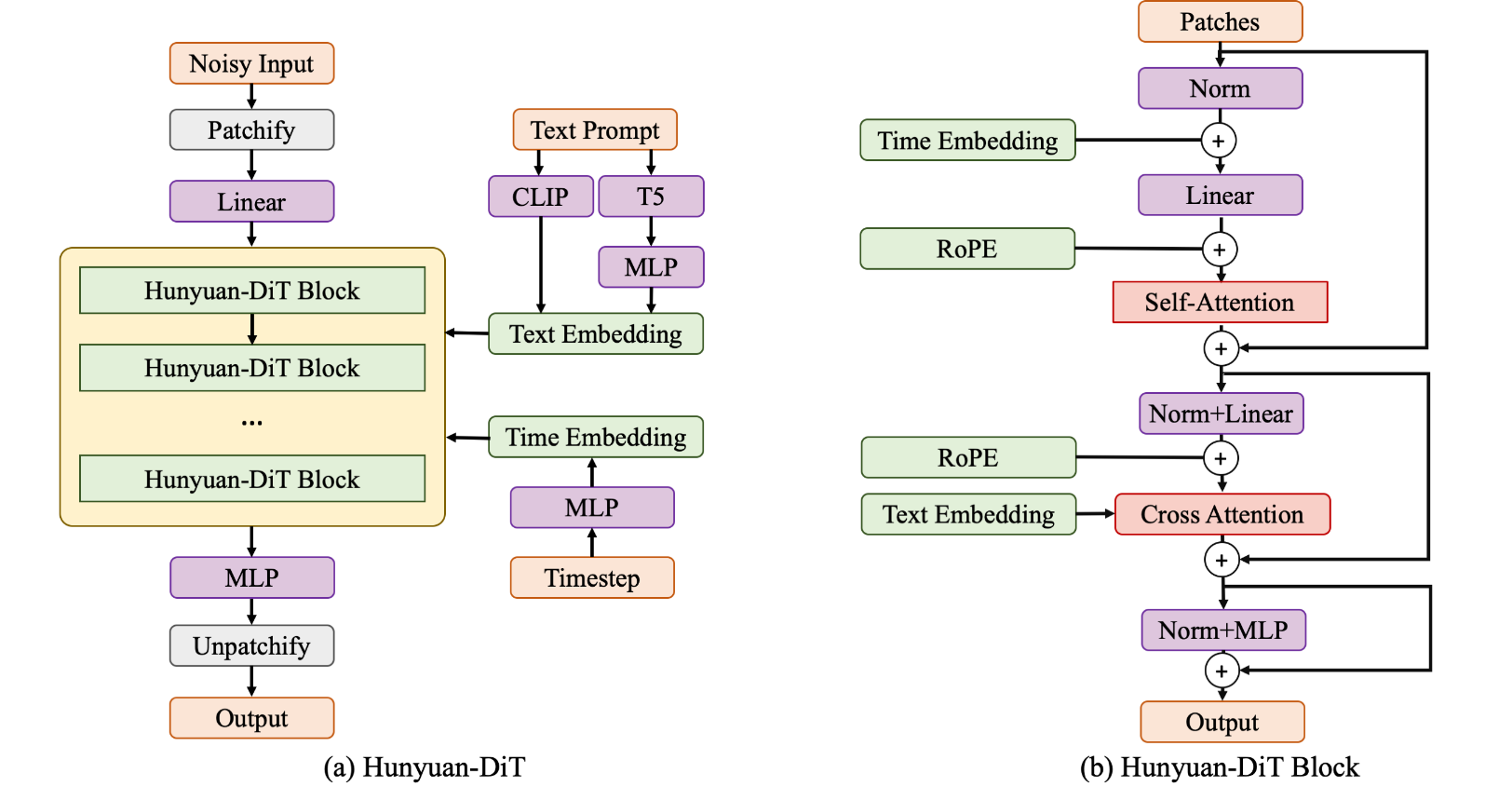
Hunyuan-DiT (2024/12/01)
Hunyuan-DiT, developed by Tencent’s Hunyuan team, aims to create a powerful multi-resolution diffusion transformer capable of fine-grained understanding of both English and Chinese languages, addressing the need for state-of-the-art Chinese-to-image generation with culturally relevant and multilingual capabilities [32]. The model establishes a comprehensive data pipeline with iterative optimization, employing a Multimodal Large Language Model to refine image captions and enhance alignment between textual descriptions and generated images, particularly for intricate Chinese characters and cultural nuances.
Architecturally, Hunyuan-DiT builds upon PixArt-$\alpha$ by incorporating both single-stream and double-stream Multi-Modal Diffusion Transformer (MM-DiT) blocks similar to SD3, enabling efficient handling of complex image generation tasks across multiple resolutions. The model integrates dual text encoders—CLIP for understanding overall semantic content and T5 [48] for nuanced language comprehension including complex sentence structures—combined with enhanced positional encoding to maintain spatial information across different resolutions, facilitating robust multi-resolution generation capabilities.
- Single-stream + double-stream MM-DiT blocks for enhanced multi-modal processing (vs single-stream cross-attention)
- Dual text encoders (CLIP + T5) for semantic and nuanced language understanding (vs T5 only)
- Multi-resolution diffusion transformer with enhanced positional encoding for robust resolution handling
- Multimodal LLM-refined captions with fine-grained bilingual (English + Chinese) understanding
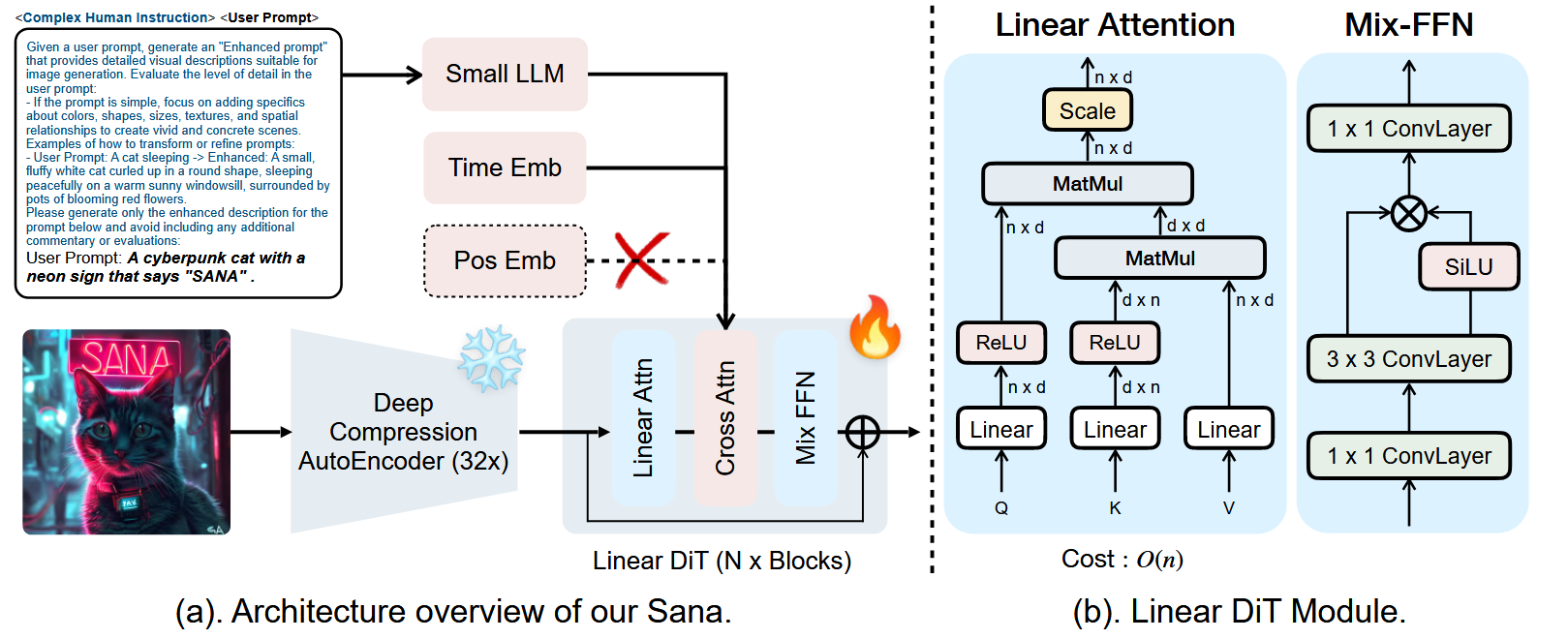
SANA (2025/01/11)
SANA, developed by NVIDIA, aims to enable efficient high-resolution image synthesis up to 4096×4096 pixels while maintaining deployment feasibility on consumer hardware, generating 1024×1024 images in under a second on a 16GB laptop GPU [33]. The model introduces innovations to reduce computational requirements dramatically: DC-AE (deep compression autoencoder) achieves 32× image compression reducing latent tokens significantly, efficient caption labeling and selection accelerate convergence, and Flow-DPM-Solver reduces sampling steps for faster generation.
Architecturally, SANA advances beyond PixArt-$\Sigma$ by replacing traditional self-attention mechanisms with Linear Diffusion Transformer (Linear DiT) blocks, enhancing computational efficiency at high resolutions without compromising quality. The model adopts a decoder-only small language model as the text encoder, employing complex human instructions with in-context learning to improve text-image alignment compared to conventional CLIP or T5 encoders. The compact 0.6B parameter model achieves competitive performance with substantially larger models like Flux-12B while being 20 times smaller and over 100 times faster in throughput.
- Linear DiT replacing traditional self-attention for O(n) complexity vs O(n²) at high resolutions
- DC-AE with 32× compression reducing latent tokens and memory requirements dramatically
- Decoder-only language model as text encoder with in-context learning (vs T5)
- 0.6B parameters achieving competitive quality with 12B models while 100× faster throughput
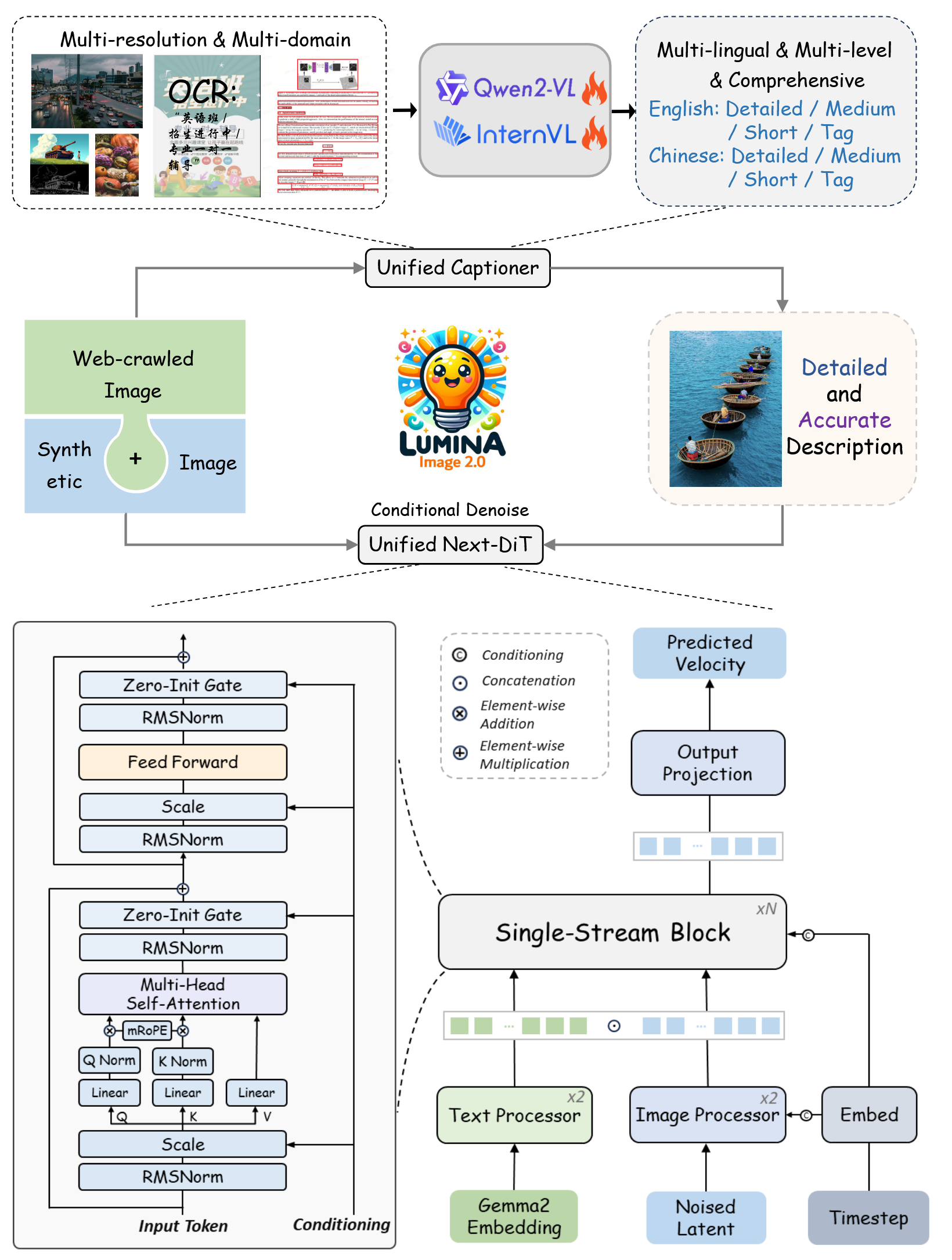
Lumina-Image 2.0 (2025/01/22)
Lumina-Image 2.0 aims to provide a unified and efficient image generative framework that excels in generating high-quality images with strong text-image alignment across diverse generation and editing tasks [34]. Building upon the Lumina series’ foundation, the model consolidates multiple generation tasks into a cohesive framework, optimizing performance and efficiency to cater to a wide range of image generation applications while achieving competitive scores across multiple benchmarks including FID and CLIP metrics.
Architecturally, Lumina-Image 2.0 advances beyond Lumina-Next-T2I by introducing a unified Next-DiT architecture that seamlessly integrates text-to-image generation and image editing capabilities within a shared framework. The model maintains the Lumina series’ architectural strengths including 3D RoPE [50], frequency-aware scaling, and flow-based formulation, while enhancing the framework to support both generation and editing operations efficiently. This unified approach enables the model to leverage shared representations and training strategies across different image generation modalities.
- Unified Next-DiT framework seamlessly integrating generation and editing (vs generation-only focus)
- Enhanced multi-task architecture supporting diverse image generation applications within single model
- Optimized training paradigm leveraging shared representations across generation modalities
- Competitive performance across FID and CLIP benchmarks with improved efficiency
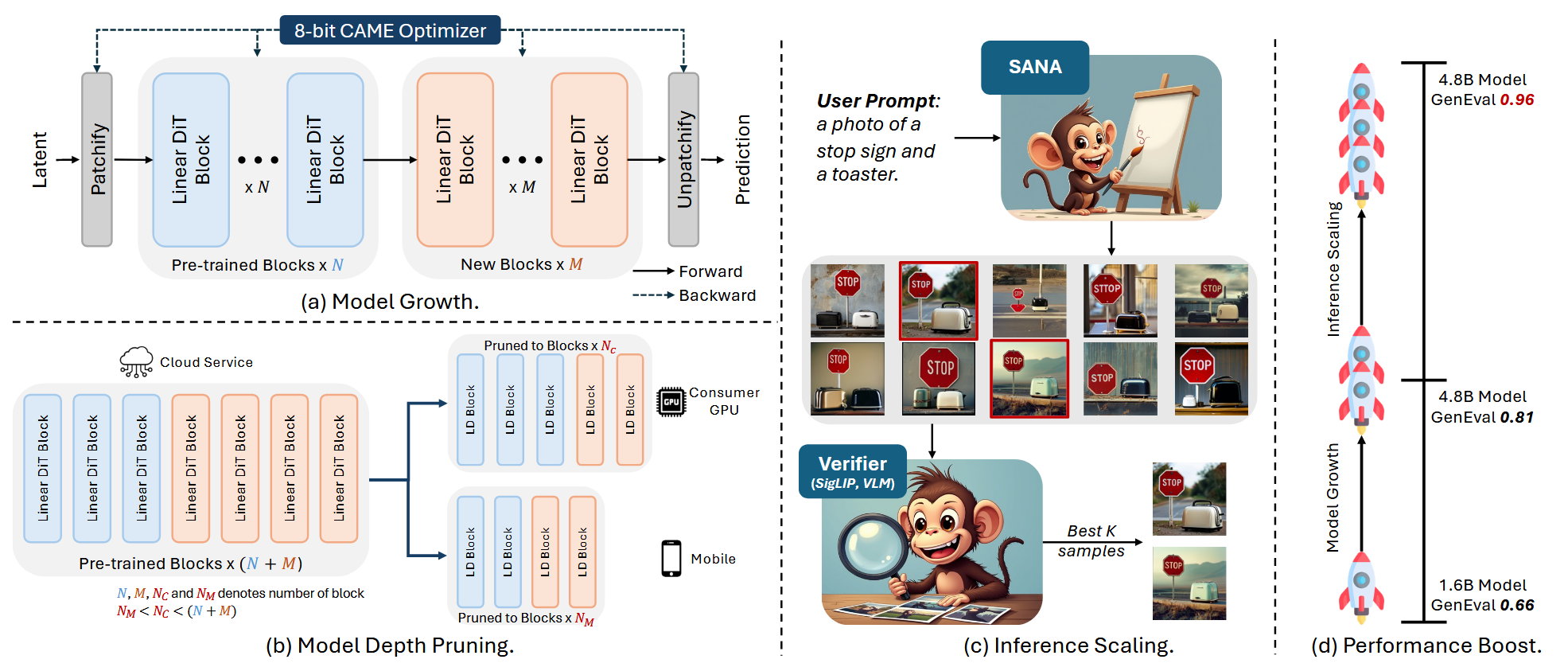
SANA 1.5 (2025/03/21)
SANA 1.5 aims to push the boundaries of efficient high-resolution image synthesis established by SANA, offering improved performance and scalability through larger model sizes and advanced inference scaling techniques [35]. The model introduces inference scaling via VISA (a specialized NVILA-2B model) that scores and selects top images from large candidate sets, significantly boosting GenEval performance scores—for instance, improving SANA-1.5-4.8B from 81 to 96. This approach demonstrates that post-generation selection can dramatically enhance quality metrics without architectural changes.
Architecturally, SANA 1.5 builds upon the original SANA by incorporating an enhanced DC-AE (deep compression autoencoder) to handle higher resolutions and more complex generation tasks, along with advanced Linear DiT blocks featuring more sophisticated linear attention mechanisms to boost efficiency and quality in high-resolution synthesis. The model scales to 4.8B parameters compared to SANA’s 0.6B, providing a robust solution for generating high-quality images with strong text-image alignment suitable for diverse professional applications requiring both quality and computational efficiency.
- Inference scaling with VISA model for candidate selection dramatically improving GenEval scores (81→96)
- Enhanced DC-AE handling higher resolutions and more complex generation tasks
- Advanced Linear DiT with more sophisticated linear attention mechanisms
- Scaled to 4.8B parameters providing improved quality while maintaining efficiency advantages
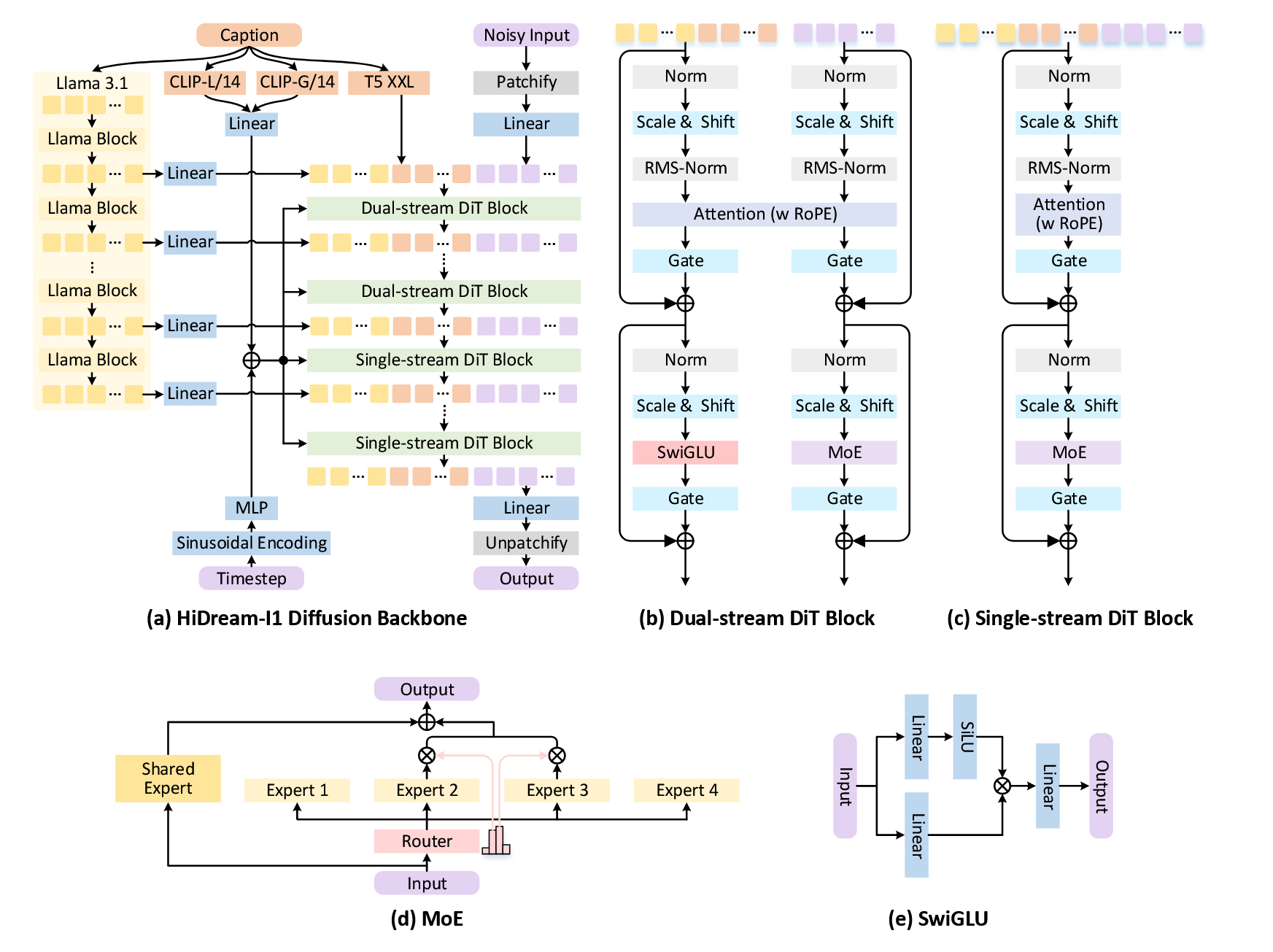
HiDream-I1-Dev (2025/04/06)
HiDream-I1, developed by HiDream.ai, addresses the critical trade-off between quality improvements and computational complexity in image generative foundation models, aiming to achieve state-of-the-art image generation quality within seconds while maintaining high efficiency [36]. With 17 billion parameters, the model introduces a sparse Diffusion Transformer structure that enables efficient inference suitable for professional-grade design needs, supporting 4K ultra-high-definition image generation with advanced text comprehension, multi-style adaptation, and precise detail control while optimizing computational requirements through sparsity.
Architecturally, HiDream-I1 advances beyond Flux.1-Dev and Qwen-Image by implementing a novel sparse DiT structure where only subsets of transformer blocks are activated for each forward pass, dramatically reducing computational costs while maintaining generation quality. The sparse architecture enables the massive 17B parameter model to achieve practical inference speeds comparable to smaller dense models, with efficient diffusion mechanisms supporting multimodal input and providing fine-grained control over generation. This sparse approach represents a paradigm shift in scaling DiT models, demonstrating that architectural efficiency through sparsity can rival quality of substantially denser models.
- Sparse DiT structure activating only subsets of blocks per forward pass for efficient 17B parameter model
- 4K ultra-high-definition generation support with optimized inference speed despite massive scale
- Advanced sparse attention mechanisms maintaining quality while dramatically reducing computational costs
- Multimodal input support and fine-grained control optimized for professional-grade design applications
CogView4-6B (2025/05/03)
CogView4-6B [31] represents the latest advancement in the CogView series, featuring a sophisticated CogView4Transformer2DModel architecture that excels in Chinese text rendering and multilingual image generation. The model demonstrates exceptional performance in text accuracy evaluation, achieving precision of 0.6969, recall of 0.5532, and F1 score of 0.6168 on Chinese text benchmarks.
CogView4-6B leverages GLM-based text encoding and advanced transformer blocks with RoPE (Rotary Position Embedding) for enhanced spatial understanding and text-image alignment. This architectural sophistication enables the model to achieve superior text rendering capabilities, particularly for complex Chinese characters and multilingual content, setting new standards for text-to-image generation in non-Latin scripts. Available on Hugging Face under Apache 2.0 license.
Qwen-Image (2025/08/04)
Qwen-Image represents a monumental scaling achievement in text-to-image synthesis, establishing a new state-of-the-art with its massive 28.85 billion parameter architecture [37]. Developed by Alibaba’s Qwen team, this flagship model aims to push the boundaries of generation quality, text-image alignment, and multimodal understanding through unprecedented scale. The model excels at generating highly detailed, photorealistic images that accurately reflect complex textual prompts, setting new benchmarks for fidelity and coherence in the field.
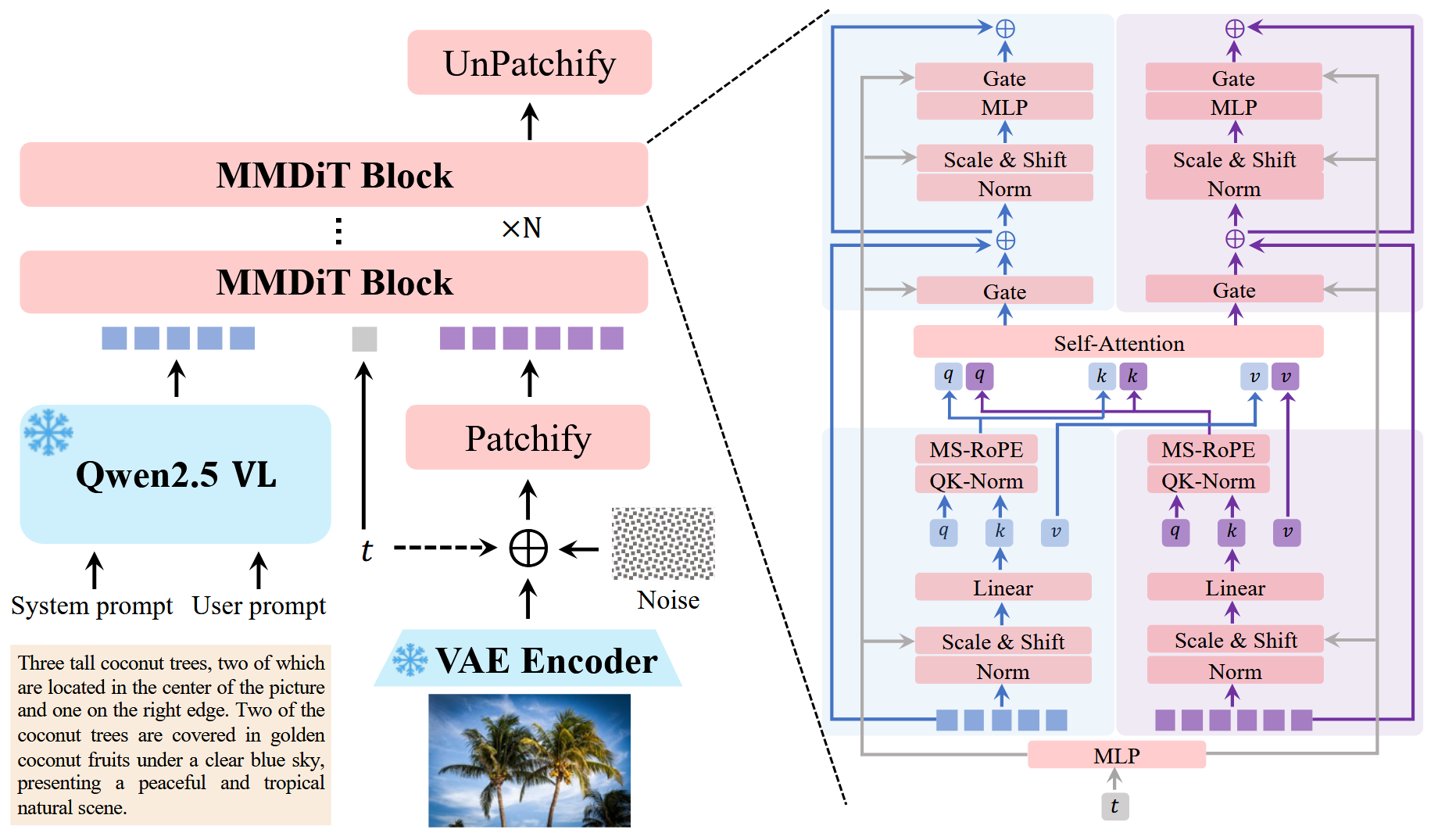
Architecturally, Qwen-Image employs a massively scaled Multi-Modal Diffusion Transformer (MMDiT) that builds upon the hybrid single- and double-stream designs seen in models like Flux.1-Dev. The generator model alone comprises over 20 billion parameters, combined with a powerful 8.29 billion parameter text encoder for unparalleled language comprehension. This dual-stream approach allows for sophisticated interaction between text and image modalities, enabling precise control over generated content. The model integrates advanced training techniques, including rectified flow and large-scale data curation, to ensure stable and efficient convergence despite its enormous size.
- Massive dense scaling to 28.85B parameters (vs HiDream's 17B sparse architecture)
- Focus on state-of-the-art quality through sheer scale (vs HiDream's focus on efficiency via sparsity)
- Extremely large 8.29B text encoder for superior text-image alignment
- Represents the pinnacle of the dense DiT scaling paradigm before potential shifts to new architectures
Experiments and Case Studies
To comprehensively evaluate the capabilities of different text-to-image diffusion models, we propose a systematic evaluation framework spanning tasks of varying complexity. This section will present case studies of text-to-image generation visualizations using existing checkpoints, assessing their performance across a spectrum of increasingly challenging tasks.
Implementation Details2:
| Parameter | Value |
|---|---|
| Precision | bfloat16 |
| Scheduler | default |
| Steps | 50 |
| Guidance Scale | 7.5 |
| Resolution | 512×512 |
- There is no strong correlation between image model size and image aesthetics (See case study 4).
- There is no strong correlation between text model size and prompt following (See case study 5).
- Large models generally work better but always the case.
- U-Nets based model perform comparativaly worse than DiTs in the similar model size, for instance, SDXL to SANA, Kandinsky-3 to CogView4.
- StaleDiffusion 3.x continously trained on higher resolution (e.g., 1024px) tends to generate croped results.
- Not all models are capable to dealing with multilingual prompt (see case study 2).
- Commercial model such as GPT-Image model works extremely well in aesthetics, prompt following, counting, text rendering and spatial reasoning.
Why Scaling Favors Attention
As diffusion models scaled in data and compute, the active bottleneck shifted from local fidelity to global semantic alignment, and the community moved accordingly: from U-Nets that hard-wire translation equivariance via convolution to Diffusion Transformers that learn equivariances through self-attention. Let $\mathcal{C}^{\mathrm{conv}}_{G}$ be the class of translation-equivariant, finite-support Toeplitz operators (U-Net convolutional kernels) and $\mathcal{A}^{\mathrm{attn}}$ the class of self-attention kernels with relative positional structure (DiTs). Write $\sqsubseteq^{\mathrm{bias}}$ as “is a constrained instance of (via inductive-bias constraints)”[55][56].
\[\boxed{ \mathcal{C}^{\mathrm{conv}}_{G}\ \sqsubseteq^{\mathrm{bias}}\ \mathcal{A}^{\mathrm{attn}} }\]In plain terms, convolution is a simplified, efficient expression of attention obtained by enforcing fixed translation symmetry, parameter tying, and locality[57][58][59][60][61]; removing these constraints yields attention without a hard-coded translation prior, allowing DiTs to learn which symmetries and long-range relations matter at scale. This inclusion explains the empirical shift under modern hardware and datasets: attention strictly generalizes convolution while retaining it as an efficient special case, delivering smoother scaling laws and higher semantic “bandwidth” per denoising step. In practice, this is also a story of hardware path dependence: attention’s dense-matrix primitives align with contemporary accelerators and compiler stacks, effectively “winning” the hardware lottery [2]. And, echoing the Bitter Lesson[1], as data and compute grow, general methods with fewer hand-engineered priors dominate—making attention’s strict generalization of convolution the natural backbone at scale.
Further Discussion
From Text-to-Image Generation to Real-World Applications
Text-to-image is now genuinely strong; the next wave is about conditioning existing pixels rather than generating from scratch—turning models into reliable editors that honor what must stay and change only what’s asked. This means prioritizing downstream tasks like image editing, inpainting/outpainting, image-to-image restyling, and structure- or reference-guided synthesis (edges, depth, layout, style, identity). The practical focus shifts from unconstrained novelty to controllable, faithful rewrites with tight mask adherence, robust subject/style preservation, and interactive latencies, so these systems plug cleanly into real creative, design, and industrial workflows.
Diffusion Models vs. Auto-regressive Models
Diffusion models and autoregressive (AR) models represent two fundamentally different approaches to image generation, with the key distinction being that autoregressive models operate on discrete image tokens while diffusion models work with continuous representations. Autoregressive models like DALL-E [62], CogView [63], and CogView2 [64] treat image generation as a sequence modeling problem, encoding images into discrete tokens using VQ-VAE [47] or similar vector quantization methods, then autoregressively predicting the next token given previous tokens. This approach offers sequential generation with precise control and natural language integration, but suffers from slow generation, error accumulation, and discrete representation loss. In contrast, diffusion models operate directly on continuous pixel or latent representations, learning to reverse a gradual noise corruption process, which enables parallel generation, high-quality outputs, and flexible conditioning, though at the cost of computational overhead and less direct control. Recent advances have significantly improved autoregressive approaches: VAR [65] redefines autoregressive learning as coarse-to-fine “next-scale prediction” and achieves superior performance compared to diffusion transformers, while Infinity [66] demonstrates effective scaling of bitwise autoregressive modeling for high-resolution synthesis. Additionally, MAR [67] bridges the gap between paradigms by adopting diffusion loss for autoregressive models, enabling continuous-valued autoregressive generation without vector quantization. Recent work has also explored hybrid approaches that combine both paradigms: HunyuanImage 3.0 [68] and BLIP3-o [69] demonstrate unified multimodal models within autoregressive frameworks while incorporating diffusion-inspired techniques, while OmniGen [70] and OmniGen2 [71] use diffusion models as backbones for unified generation capabilities.
Note: This blog post’s knowledge cutoff is November 17, 2025. For the latest developments, we refer readers to recent works including DiP [80], DeCo [81], PixelDiT [82], Z-Image [83], FLUX.2 [84], and LongCat-Image for readers to explore.
References
- Sutton, Rich (2019). The Bitter Lesson. https://www.cs.utexas.edu/~eunsol/courses/data/bitter_lesson.pdf
- Hooker, Sara (2021). The Hardware Lottery. https://dl.acm.org/doi/10.1145/3467017
- Weng, Lilian (2021). What Are Diffusion Models?. https://lilianweng.github.io/posts/2021-07-11-diffusion-models/
- Yang, Song (2019). Generative Modeling by Estimating Gradients of the Data Distribution. https://yang-song.net/blog/2021/score/
- Ronneberger, Olaf, Fischer, Philipp, & Brox, Thomas (2015). U-Net: Convolutional Networks for Biomedical Image Segmentation. MICCAI. http://link.springer.com/10.1007/978-3-319-24574-4_28
- Lin, Guosheng, Milan, Anton, Shen, Chunhua, & Reid, Ian (2017). RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation. CVPR. https://openaccess.thecvf.com/content_cvpr_2017/html/Lin_RefineNet_Multi-Path_Refinement_CVPR_2017_paper.html
- Salimans, Tim, Karpathy, Andrej, Chen, Xi, & Kingma, Diederik P. (2017). PixelCNN++: Improving the PixelCNN with Discretized Logistic Mixture Likelihood and Other Modifications. ICLR. https://openreview.net/forum?id=BJrFC6ceg
- Ho, Jonathan, Jain, Ajay, & Abbeel, Pieter (2020). Denoising Diffusion Probabilistic Models. NeurIPS. https://proceedings.neurips.cc/paper/2020/hash/4c5bcfec8584af0d967f1ab10179ca4b-Abstract.html
- Song, Yang & Ermon, Stefano (2020). Improved Techniques for Training Score-Based Generative Models. NeurIPS.
- Nichol, Alexander Quinn & Dhariwal, Prafulla (2021). Improved Denoising Diffusion Probabilistic Models. ICML. https://proceedings.mlr.press/v139/nichol21a.html
- Dhariwal, Prafulla & Nichol, Alexander (2021). Diffusion Models Beat GANs on Image Synthesis. NeurIPS. https://proceedings.neurips.cc/paper_files/paper/2021/hash/49ad23d1ec9fa4bd8d77d02681df5cfa-Abstract.html
- Song, Yang, Sohl-Dickstein, Jascha, Kingma, Diederik P., Kumar, Abhishek, Ermon, Stefano, & Poole, Ben (2021). Score-Based Generative Modeling through Stochastic Differential Equations. ICLR. https://openreview.net/forum?id=PxTIG12RRHS&utm_campaign=NLP%20News&utm_medium=email&utm_source=Revue%20newsletter
- Rombach, Robin, Blattmann, Andreas, Lorenz, Dominik, Esser, Patrick, & Ommer, Björn (2022). High-Resolution Image Synthesis With Latent Diffusion Models. CVPR. https://openaccess.thecvf.com/content/CVPR2022/html/Rombach_High-Resolution_Image_Synthesis_With_Latent_Diffusion_Models_CVPR_2022_paper.html
- Razzhigaev, Anton, Shakhmatov, Arseniy, Maltseva, Anastasia, Arkhipkin, Vladimir, Pavlov, Igor, Ryabov, Ilya, Kuts, Angelina, Panchenko, Alexander, Kuznetsov, Andrey, & Dimitrov, Denis (2023). Kandinsky: an Improved Text-to-Image Synthesis with Image Prior and Conditional Diffusion Models. EMNLP. https://openreview.net/forum?id=Vmg2GxSbKn
- Bao, Fan, Nie, Shen, Xue, Kaiwen, Li, Chongxuan, Pu, Shi, Wang, Yaole, Yue, Gang, Cao, Yue, Su, Hang, & Zhu, Jun (2023). One Transformer Fits All Distributions in Multi-Modal Diffusion at Scale. ICML. https://openreview.net/forum?id=Urp3atR1Z3
- Podell, Dustin, English, Zion, Lacey, Kyle, Blattmann, Andreas, Dockhorn, Tim, Müller, Jonas, Penna, Joe, & Rombach, Robin (2024). SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis. ICLR. https://openreview.net/forum?id=di52zR8xgf
- Arkhipkin, Vladimir, Filatov, Andrei, Vasilev, Viacheslav, Maltseva, Anastasia, Azizov, Said, Pavlov, Igor, Agafonova, Julia, Kuznetsov, Andrey, & Dimitrov, Denis (2024). Kandinsky 3.0 Technical Report. http://arxiv.org/abs/2312.03511
- Arkhipkin, Vladimir, Vasilev, Viacheslav, Filatov, Andrei, Pavlov, Igor, Agafonova, Julia, Gerasimenko, Nikolai, Averchenkova, Anna, Mironova, Evelina, Bukashkin, Anton, Kulikov, Konstantin, Kuznetsov, Andrey, & Dimitrov, Denis (2024). Kandinsky 3: Text-to-Image Synthesis for Multifunctional Generative Framework. EMNLP. https://aclanthology.org/2024.emnlp-demo.48/
- Pernias, Pablo, Rampas, Dominic, Richter, Mats Leon, Pal, Christopher, & Aubreville, Marc (2024). Würstchen: An Efficient Architecture for Large-Scale Text-to-Image Diffusion Models. ICLR. https://openreview.net/forum?id=gU58d5QeGv
- Vahdat, Arash, Song, Jiaming, & Meng, Chenlin (2023). CVPR 2023 Tutorial Denoising Diffusion-based Generative Modeling: Foundation and Applications. https://cvpr2023-tutorial-diffusion-models.github.io
- Ho, Jonathan, Saharia, Chitwan, Chan, William, Fleet, David J., Norouzi, Mohammad, & Salimans, Tim (2022). Cascaded Diffusion Models for High Fidelity Image Generation. JMLR.
- Saharia, Chitwan, Ho, Jonathan, Chan, William, Salimans, Tim, Fleet, David J, & Norouzi, Mohammad (2022). Image super-resolution via iterative refinement. TPAMI.
- Bao, Fan, Nie, Shen, Xue, Kaiwen, Cao, Yue, Li, Chongxuan, Su, Hang, & Zhu, Jun (2023). All Are Worth Words: A ViT Backbone for Diffusion Models. CVPR. https://openaccess.thecvf.com/content/CVPR2023/html/Bao_All_Are_Worth_Words_A_ViT_Backbone_for_Diffusion_Models_CVPR_2023_paper.html
- Peebles, William & Xie, Saining (2023). Scalable Diffusion Models with Transformers. ICCV. https://openaccess.thecvf.com/content/ICCV2023/html/Peebles_Scalable_Diffusion_Models_with_Transformers_ICCV_2023_paper.html
- Chen, Junsong, Yu, Jincheng, Ge, Chongjian, Yao, Lewei, Xie, Enze, Wang, Zhongdao, Kwok, James, Luo, Ping, Lu, Huchuan, & Li, Zhenguo (2024). PixArt-α: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis. ICLR. https://openreview.net/forum?id=eAKmQPe3m1
- Gao, Peng, Zhuo, Le, Liu, Dongyang, Du, Ruoyi, Luo, Xu, Qiu, Longtian, Zhang, Yuhang, Huang, Rongjie, Geng, Shijie, Zhang, Renrui, Xie, Junlin, Shao, Wenqi, Jiang, Zhengkai, Yang, Tianshuo, Ye, Weicai, He, Tong, He, Jingwen, He, Junjun, Qiao, Yu, & Li, Hongsheng (2025). Lumina-T2X: Scalable Flow-based Large Diffusion Transformer for Flexible Resolution Generation. ICLR. https://openreview.net/forum?id=EbWf36quzd
- Chen, Junsong, Ge, Chongjian, Xie, Enze, Wu, Yue, Yao, Lewei, Ren, Xiaozhe, Wang, Zhongdao, Luo, Ping, Lu, Huchuan, & Li, Zhenguo (2024). PIXART-Σ: Weak-to-Strong Training of Diffusion Transformer for 4K Text-to-Image Generation. ECCV.
- Zhuo, Le, Du, Ruoyi, Xiao, Han, Li, Yangguang, Liu, Dongyang, Huang, Rongjie, Liu, Wenze, Zhu, Xiangyang, Wang, Fu-Yun, Ma, Zhanyu, Luo, Xu, Wang, Zehan, Zhang, Kaipeng, Zhao, Lirui, Liu, Si, Yue, Xiangyu, Ouyang, Wanli, Qiao, Yu, Li, Hongsheng, & Gao, Peng (2024). Lumina-Next: Making Lumina-T2X Stronger and Faster with Next-DiT. NeurIPS. https://openreview.net/forum?id=ieYdf9TZ2u
- Esser, Patrick, Kulal, Sumith, Blattmann, Andreas, Entezari, Rahim, Müller, Jonas, Saini, Harry, Levi, Yam, Lorenz, Dominik, Sauer, Axel, Boesel, Frederic, Podell, Dustin, Dockhorn, Tim, English, Zion, & Rombach, Robin (2024). Scaling Rectified Flow Transformers for High-Resolution Image Synthesis. ICML. https://openreview.net/forum?id=FPnUhsQJ5B
- BlackForestLabs (2025). FLUX.1. https://blackforestlabs.io/flux-1/
- Zheng, Wendi, Teng, Jiayan, Yang, Zhuoyi, Wang, Weihan, Chen, Jidong, Gu, Xiaotao, Dong, Yuxiao, Ding, Ming, & Tang, Jie (2024). CogView3: Finer and Faster Text-to-Image Generation via Relay Diffusion. ECCV.
- Li, Zhimin, Zhang, Jianwei, Lin, Qin, Xiong, Jiangfeng, Long, Yanxin, Deng, Xinchi, Zhang, Yingfang, Liu, Xingchao, Huang, Minbin, Xiao, Zedong, Chen, Dayou, He, Jiajun, Li, Jiahao, Li, Wenyue, Zhang, Chen, Quan, Rongwei, Lu, Jianxiang, Huang, Jiabin, Yuan, Xiaoyan, Zheng, Xiaoxiao, Li, Yixuan, Zhang, Jihong, Zhang, Chao, Chen, Meng, Liu, Jie, Fang, Zheng, Wang, Weiyan, Xue, Jinbao, Tao, Yangyu, Zhu, Jianchen, Liu, Kai, Lin, Sihuan, Sun, Yifu, Li, Yun, Wang, Dongdong, Chen, Mingtao, Hu, Zhichao, Xiao, Xiao, Chen, Yan, Liu, Yuhong, Liu, Wei, Wang, Di, Yang, Yong, Jiang, Jie, & Lu, Qinglin (2024). Hunyuan-DiT: A Powerful Multi-Resolution Diffusion Transformer with Fine-Grained Chinese Understanding. http://arxiv.org/abs/2405.08748
- Xie, Enze, Chen, Junsong, Chen, Junyu, Cai, Han, Tang, Haotian, Lin, Yujun, Zhang, Zhekai, Li, Muyang, Zhu, Ligeng, Lu, Yao, & Han, Song (2025). SANA: Efficient High-Resolution Text-to-Image Synthesis with Linear Diffusion Transformers. ICLR. https://openreview.net/forum?id=N8Oj1XhtYZ
- Qin, Qi, Zhuo, Le, Xin, Yi, Du, Ruoyi, Li, Zhen, Fu, Bin, Lu, Yiting, Yuan, Jiakang, Li, Xinyue, Liu, Dongyang, Zhu, Xiangyang, Zhang, Manyuan, Beddow, Will, Millon, Erwann, Perez, Victor, Wang, Wenhai, He, Conghui, Zhang, Bo, Liu, Xiaohong, Li, Hongsheng, Qiao, Yu, Xu, Chang, & Gao, Peng (2025). Lumina-Image 2.0: A Unified and Efficient Image Generative Framework. http://arxiv.org/abs/2503.21758
- Xie, Enze, Chen, Junsong, Zhao, Yuyang, Yu, Jincheng, Zhu, Ligeng, Lin, Yujun, Zhang, Zhekai, Li, Muyang, Chen, Junyu, Cai, Han, Liu, Bingchen, Zhou, Daquan, & Han, Song (2025). SANA 1.5: Efficient Scaling of Training-Time and Inference-Time Compute in Linear Diffusion Transformer. ICML. https://openreview.net/forum?id=27hOkXzy9e
- Cai, Qi, Chen, Jingwen, Chen, Yang, Li, Yehao, Long, Fuchen, Pan, Yingwei, Qiu, Zhaofan, Zhang, Yiheng, Gao, Fengbin, Xu, Peihan, Wang, Yimeng, Yu, Kai, Chen, Wenxuan, Feng, Ziwei, Gong, Zijian, Pan, Jianzhuang, Peng, Yi, Tian, Rui, Wang, Siyu, Zhao, Bo, Yao, Ting, & Mei, Tao (2025). HiDream-I1: A High-Efficient Image Generative Foundation Model with Sparse Diffusion Transformer. http://arxiv.org/abs/2505.22705
- Team, Qwen (2025). Qwen-Image Technical Report. http://arxiv.org/abs/2508.02324
- Gao, Shanghua, Zhou, Pan, Cheng, Ming-Ming, & Yan, Shuicheng (2023). Masked Diffusion Transformer Is a Strong Image Synthesizer. https://openaccess.thecvf.com/content/ICCV2023/html/Gao_Masked_Diffusion_Transformer_is_a_Strong_Image_Synthesizer_ICCV_2023_paper.html
- Gao, Shanghua, Zhou, Pan, Cheng, Ming-Ming, & Yan, Shuicheng (2024). MDTv2: Masked Diffusion Transformer Is a Strong Image Synthesizer. http://arxiv.org/abs/2303.14389
- Zheng, Hongkai, Nie, Weili, Vahdat, Arash, & Anandkumar, Anima (2024). Fast Training of Diffusion Models with Masked Transformers. TMLR. https://openreview.net/forum?id=vTBjBtGioE
- Yu, Sihyun, Kwak, Sangkyung, Jang, Huiwon, Jeong, Jongheon, Huang, Jonathan, Shin, Jinwoo, & Xie, Saining (2025). Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think. ICLR. https://openreview.net/forum?id=DJSZGGZYVi
- Wu, Ge, Zhang, Shen, Shi, Ruijing, Gao, Shanghua, Chen, Zhenyuan, Wang, Lei, Chen, Zhaowei, Gao, Hongcheng, Tang, Yao, Yang, Jian, Cheng, Ming-Ming, & Li, Xiang (2025). Representation Entanglement for Generation: Training Diffusion Transformers Is Much Easier Than You Think. http://arxiv.org/abs/2507.01467
- Wang, Shuai, Tian, Zhi, Huang, Weilin, & Wang, Limin (2025). DDT: Decoupled Diffusion Transformer. http://arxiv.org/abs/2504.05741
- Tian, Yuchuan, Tu, Zhijun, Chen, Hanting, Hu, Jie, Xu, Chao, & Wang, Yunhe (2024). U-DiTs: Downsample Tokens in U-Shaped Diffusion Transformers. NeurIPS. https://proceedings.neurips.cc/paper_files/paper/2024/hash/5d2e24df9cfaad3189833b819c40b392-Abstract-Conference.html
- Zheng, Boyang, Ma, Nanye, Tong, Shengbang, & Xie, Saining (2025). Diffusion Transformers with Representation Autoencoders. http://arxiv.org/abs/2510.11690
- Chen, Bowei, Bi, Sai, Tan, Hao, Zhang, He, Zhang, Tianyuan, Li, Zhengqi, Xiong, Yuanjun, Zhang, Jianming, & Zhang, Kai (2025). Aligning Visual Foundation Encoders to Tokenizers for Diffusion Models. http://arxiv.org/abs/2509.25162
- Esser, Patrick, Rombach, Robin, & Ommer, Bjorn (2021). Taming Transformers for High-Resolution Image Synthesis. CVPR. https://openaccess.thecvf.com/content/CVPR2021/html/Esser_Taming_Transformers_for_High-Resolution_Image_Synthesis_CVPR_2021_paper.html?ref=
- Raffel, Colin, Shazeer, Noam, Roberts, Adam, Lee, Katherine, Narang, Sharan, Matena, Michael, Zhou, Yanqi, Li, Wei, & Liu, Peter J. (2020). Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. JMLR. http://jmlr.org/papers/v21/20-074.html
- Xue, Zeyue, Song, Guanglu, Guo, Qiushan, Liu, Boxiao, Zong, Zhuofan, Liu, Yu, & Luo, Ping (2023). RAPHAEL: Text-to-Image Generation via Large Mixture of Diffusion Paths. NeurIPS. https://proceedings.neurips.cc/paper_files/paper/2023/hash/821655c7dc4836838cd8524d07f9d6fd-Abstract-Conference.html
- Su, Jianlin, Ahmed, Murtadha, Lu, Yu, Pan, Shengfeng, Bo, Wen, & Liu, Yunfeng (2024). RoFormer: Enhanced Transformer with Rotary Position Embedding. Neurocomput. https://doi.org/10.1016/j.neucom.2023.127063
- Henry, Alex, Dachapally, Prudhvi Raj, Pawar, Shubham Shantaram, & Chen, Yuxuan (2020). Query-Key Normalization for Transformers. Findings of the Association for Computational Linguistics: EMNLP 2020. https://aclanthology.org/2020.findings-emnlp.379/
- Touvron, Hugo, Martin, Louis, Stone, Kevin, Albert, Peter, Almahairi, Amjad, Babaei, Yasmine, Bashlykov, Nikolay, Batra, Soumya, Bhargava, Prajjwal, Bhosale, Shruti, Bikel, Dan, Blecher, Lukas, Canton Ferrer, Cristian, Chen, Moya, Cucurull, Guillem, Esiobu, David, Fernandes, Jude, Fu, Jeremy, Fu, Wenyin, Fuller, Brian, Gao, Cynthia, Goswami, Vedanuj, Goyal, Naman, Hartshorn, Anthony, Hosseini, Saghar, Hou, Rui, Inan, Hakan, Kardas, Marcin, Kerkez, Viktor, Khabsa, Madian, Kloumann, Isabel, Korenev, Artem, Koura, Punit Singh, Lachaux, Marie-Anne, Lavril, Thibaut, Lee, Jenya, Liskovich, Diana, Lu, Yinghai, Mao, Yuning, Martinet, Xavier, Mihaylov, Todor, Mishra, Pushkar, Molybog, Igor, Nie, Yixin, Poulton, Andrew, Reizenstein, Jeremy, Rungta, Rashi, Saladi, Kalyan, Schelten, Alan, Silva, Ruan, Smith, Eric Michael, Subramanian, Ranjan, Tan, Xiaoqing Ellen, Tang, Binh, Taylor, Ross, Williams, Adina, Kuan, Jian Xiang, Xu, Puxin, Yan, Zheng, Zarov, Iliyan, Zhang, Yuchen, Fan, Angela, Kambadur, Melanie, Narang, Sharan, Rodriguez, Aurelien, Stojnic, Robert, Edunov, Sergey, & Scialom, Thomas (2023). Llama 2: Open Foundation and Fine-Tuned Chat Models. http://arxiv.org/abs/2307.09288
- Labs, Black Forest, Batifol, Stephen, Blattmann, Andreas, Boesel, Frederic, Consul, Saksham, Diagne, Cyril, Dockhorn, Tim, English, Jack, English, Zion, Esser, Patrick, Kulal, Sumith, Lacey, Kyle, Levi, Yam, Li, Cheng, Lorenz, Dominik, Müller, Jonas, Podell, Dustin, Rombach, Robin, Saini, Harry, Sauer, Axel, & Smith, Luke (2025). FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space. http://arxiv.org/abs/2506.15742
- Teng, Jiayan, Zheng, Wendi, Ding, Ming, Hong, Wenyi, Wangni, Jianqiao, Yang, Zhuoyi, & Tang, Jie (2024). Relay Diffusion: Unifying diffusion process for coarse-to-fine generation. ICLR. https://openreview.net/forum?id=qTlcbLSm4p
- Horn, Max, Shridhar, Kumar, Groenewald, Elrich, & Baumann, Philipp F. M. (2021). Translational Equivariance in Kernelizable Attention. http://arxiv.org/abs/2102.07680
- Tai, Xue-Cheng, Liu, Hao, Chan, Raymond H., & Li, Lingfeng (2024). A Mathematical Explanation of UNet. http://arxiv.org/abs/2410.04434
- Ramachandran, Prajit, Parmar, Niki, Vaswani, Ashish, Bello, Irwan, Levskaya, Anselm, & Shlens, Jon (2019). Stand-Alone Self-Attention in Vision Models. NeurIPS. https://proceedings.neurips.cc/paper/2019/hash/3416a75f4cea9109507cacd8e2f2aefc-Abstract.html
- Cordonnier, Jean-Baptiste, Loukas, Andreas, & Jaggi, Martin (2020). On the Relationship between Self-Attention and Convolutional Layers. https://openreview.net/forum?id=HJlnC1rKPB
- Chang, Tyler A., Xu, Yifan, Xu, Weijian, & Tu, Zhuowen (2021). Convolutions and Self-Attention: Re-interpreting Relative Positions in Pre-trained Language Models. ACL. https://aclanthology.org/2021.acl-long.333/
- Choi, Jeongwhan, Wi, Hyowon, Kim, Jayoung, Shin, Yehjin, Lee, Kookjin, Trask, Nathaniel, & Park, Noseong (2024). Graph Convolutions Enrich the Self-Attention in Transformers!. Advances in Neural Information Processing Systems. https://proceedings.neurips.cc/paper_files/paper/2024/hash/5eceb48c3bc8b5d936c05ff8e2ece65e-Abstract-Conference.html
- Joshi, Chaitanya K. (2025). Transformers Are Graph Neural Networks. http://arxiv.org/abs/2506.22084
- Ramesh, Aditya, Pavlov, Mikhail, Goh, Gabriel, Gray, Scott, Voss, Chelsea, Radford, Alec, Chen, Mark, & Sutskever, Ilya (2021). Zero-Shot Text-to-Image Generation. ICML. https://proceedings.mlr.press/v139/ramesh21a.html
- Ding, Ming, Yang, Zhuoyi, Hong, Wenyi, Zheng, Wendi, Zhou, Chang, Yin, Da, Lin, Junyang, Zou, Xu, Shao, Zhou, Yang, Hongxia, & Tang, Jie (2021). CogView: Mastering Text-to-Image Generation via Transformers. NeurIPS. https://www.semanticscholar.org/paper/CogView%3A-Mastering-Text-to-Image-Generation-via-Ding-Yang/1197ae4a62f0e0e4e3f3fb70396b5ff06ef371aa
- Ding, Ming, Zheng, Wendi, Hong, Wenyi, & Tang, Jie (2022). CogView2: Faster and Better Text-to-Image Generation via Hierarchical Transformers. NeurIPS. https://openreview.net/forum?id=GkDbQb6qu_r
- Tian, Keyu, Jiang, Yi, Yuan, Zehuan, Peng, Bingyue, & Wang, Liwei (2024). Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction. NeurIPS. https://openreview.net/forum?id=gojL67CfS8¬eId=GKzcnWCV21
- Han, Jian, Liu, Jinlai, Jiang, Yi, Yan, Bin, Zhang, Yuqi, Yuan, Zehuan, Peng, Bingyue, & Liu, Xiaobing (2025). Infinity: Scaling Bitwise AutoRegressive Modeling for High-Resolution Image Synthesis. CVPR. https://openaccess.thecvf.com/content/CVPR2025/html/Han_Infinity_Scaling_Bitwise_AutoRegressive_Modeling_for_High-Resolution_Image_Synthesis_CVPR_2025_paper.html
- Li, Tianhong, Tian, Yonglong, Li, He, Deng, Mingyang, & He, Kaiming (2024). Autoregressive Image Generation without Vector Quantization. NeurIPS. https://openreview.net/forum?id=VHbCa8NWpt
- Cao, Siyu, Chen, Hangting, Chen, Peng, Cheng, Yiji, Cui, Yutao, Deng, Xinchi, Dong, Ying, Gong, Kipper, Gu, Tianpeng, Gu, Xiusen, Hang, Tiankai, Huang, Duojun, Jiang, Jie, Jiang, Zhengkai, Kong, Weijie, Li, Changlin, Li, Donghao, Li, Junzhe, Li, Xin, Li, Yang, Li, Zhenxi, Li, Zhimin, Lin, Jiaxin, Linus, Liu, Lucaz, Liu, Shu, Liu, Songtao, Liu, Yu, Liu, Yuhong, Long, Yanxin, Lu, Fanbin, Lu, Qinglin, Peng, Yuyang, Peng, Yuanbo, Shen, Xiangwei, Shi, Yixuan, Tao, Jiale, Tao, Yangyu, Tian, Qi, Wan, Pengfei, Wang, Chunyu, Wang, Kai, Wang, Lei, Wang, Linqing, Wang, Lucas, Wang, Qixun, Wang, Weiyan, Wen, Hao, Wu, Bing, Wu, Jianbing, Wu, Yue, Xie, Senhao, Yang, Fang, Yang, Miles, Yang, Xiaofeng, Yang, Xuan, Yang, Zhantao, Yu, Jingmiao, Yuan, Zheng, Zhang, Chao, Zhang, Jian-Wei, Zhang, Peizhen, Zhang, Shi-Xue, Zhang, Tao, Zhang, Weigang, Zhang, Yepeng, Zhang, Yingfang, Zhang, Zihao, Zhang, Zijian, Zhao, Penghao, Zhao, Zhiyuan, Zhe, Xuefei, Zhu, Jianchen, & Zhong, Zhao (2025). HunyuanImage 3.0 Technical Report. http://arxiv.org/abs/2509.23951
- Chen, Jiuhai, Xu, Zhiyang, Pan, Xichen, Hu, Yushi, Qin, Can, Goldstein, Tom, Huang, Lifu, Zhou, Tianyi, Xie, Saining, Savarese, Silvio, Xue, Le, Xiong, Caiming, & Xu, Ran (2025). BLIP3-o: A Family of Fully Open Unified Multimodal Models—Architecture, Training and Dataset. http://arxiv.org/abs/2505.09568
- Xiao, Shitao, Wang, Yueze, Zhou, Junjie, Yuan, Huaying, Xing, Xingrun, Yan, Ruiran, Wang, Shuting, Huang, Tiejun, & Liu, Zheng (2024). OmniGen: Unified Image Generation. http://arxiv.org/abs/2409.11340
- Wu, Chenyuan, Zheng, Pengfei, Yan, Ruiran, Xiao, Shitao, Luo, Xin, Wang, Yueze, Li, Wanli, Jiang, Xiyan, Liu, Yexin, Zhou, Junjie, Liu, Ze, Xia, Ziyi, Li, Chaofan, Deng, Haoge, Wang, Jiahao, Luo, Kun, Zhang, Bo, Lian, Defu, Wang, Xinlong, Wang, Zhongyuan, Huang, Tiejun, & Liu, Zheng (2025). OmniGen2: Exploration to Advanced Multimodal Generation. http://arxiv.org/abs/2506.18871
- Hoogeboom, Emiel, Heek, Jonathan, & Salimans, Tim (2023). Simple Diffusion: End-to-end Diffusion for High Resolution Images.
- Hoogeboom, Emiel, Mensink, Thomas, Heek, Jonathan, Lamerigts, Kay, Gao, Ruiqi, & Salimans, Tim (2025). Simpler Diffusion: 1.5 FID on ImageNet512 with Pixel-Space Diffusion. CVPR.
- Lu, Zeyu, Wang, ZiDong, Huang, Di, Wu, Chengyue, Liu, Xihui, Ouyang, Wanli, & Bai, Lei (2024). FiT: Flexible Vision Transformer for Diffusion Model. ICML.
- Zhu, Lianghui, Huang, Zilong, Liao, Bencheng, Liew, Jun Hao, Yan, Hanshu, Feng, Jiashi, & Wang, Xinggang (2025). DiG: Scalable and Efficient Diffusion Models with Gated Linear Attention. CVPR.
- Li, Tianhong & He, Kaiming (2025). Back to Basics: Let Denoising Generative Models Denoise.
- Nguyen, Duy Kien, Assran, Mido, Jain, Unnat, Oswald, Martin R., Snoek, Cees G. M., & Chen, Xinlei (2025). An Image Is Worth More Than 16x16 Patches: Exploring Transformers on Individual Pixels. ICLR.
- Ma, Nanye, Goldstein, Mark, Albergo, Michael S., Boffi, Nicholas M., Vanden-Eijnden, Eric, & Xie, Saining (2024). SiT: Exploring Flow and Diffusion-Based Generative Models with Scalable Interpolant Transformers. ECCV.
- Wang, Jiahao, Kang, Ning, Yao, Lewei, Chen, Mengzhao, Wu, Chengyue, Zhang, Songyang, & Xue, Shuchen (2025). LiT: Delving into a Simple Linear Diffusion Transformer for Image Generation. ICCV.
- Chen, Zhennan, Zhu, Junwei, Chen, Xu, Zhang, Jiangning, Hu, Xiaobin, Zhao, Hanzhen, Wang, Chengjie, Yang, Jian, & Tai, Ying (2025). DiP: Taming Diffusion Models in Pixel Space.
- Ma, Zehong, Wei, Longhui, Wang, Shuai, Zhang, Shiliang, & Tian, Qi (2025). DeCo: Frequency-Decoupled Pixel Diffusion for End-to-End Image Generation.
- Yu, Yongsheng, Xiong, Wei, Nie, Weili, Sheng, Yichen, Liu, Shiqiu, & Luo, Jiebo (2025). PixelDiT: Pixel Diffusion Transformers for Image Generation.
- Tongyi Lab (2025). Z-Image: An Efficient Image Generation Foundation Model with Single-Stream Diffusion Transformer.
- Black Forest Labs (2025). FLUX.2: Frontier Visual Intelligence. https://bfl.ai/blog/flux-2
-
In the prioring work of LDM in the paper [13], the VAE part is adopted a VQ-GAN style from [47]. When it comes to CompVis Stable Diffusion v1.1-v.1.4 and StabilityAI Stable Diffusion v1.5 and v2.x version, the VAE part is turned to AutoEncoderKL style rather than a VQ style. ↩
-
For commercial model, we use ChatGPT webui GPT-5-Instant with the same prompt for each case study for image generation with a default image size as 1024 × 1024 ↩